On Detecting Significant Changes In Performance
Embedded in the very nature of adaptive systems is the ability to react to change - whenever there is a significant change in the parameters of the system or the surrounding environment, an adaptation is triggered. Common performance parameters, such as throughput or latency, are often among the triggers - however, deciding whether the observed change in performance is significant enough to warrant an adaptation is not an easy task.
To illustrate the difficulties, consider the ASCENS Cloud Case Study. A cloud application would often exhibit decreasing performance when faced with excessive workload - and an adaptive cloud application would react to this situation by allocating more processing capacity from the cloud. We pick one such application - an example XML processing server - and look at how such reactive adaptation works.
Our adaptation mechanism measures the request processing time and when the time exceeds a threshold, it launches a new XML processing server instance. From early testing, we know that the server should exhibit an average request processing time of around 100 ms. We use this average plus some slack to set the threshold - but when we deploy the application, the very first request processing time we collect is over 900 ms, well above even a very liberal threshold!
Obviously, the very first request cannot represent an excessive workload. We therefore turn to another obvious explanation, declaring the initial measurement distorted and therefore invalid. It is common to collect multiple measurements to filter out distortions, however, we cannot wait for too many measurements because that would increase the reaction time. We start with 30 measurements: 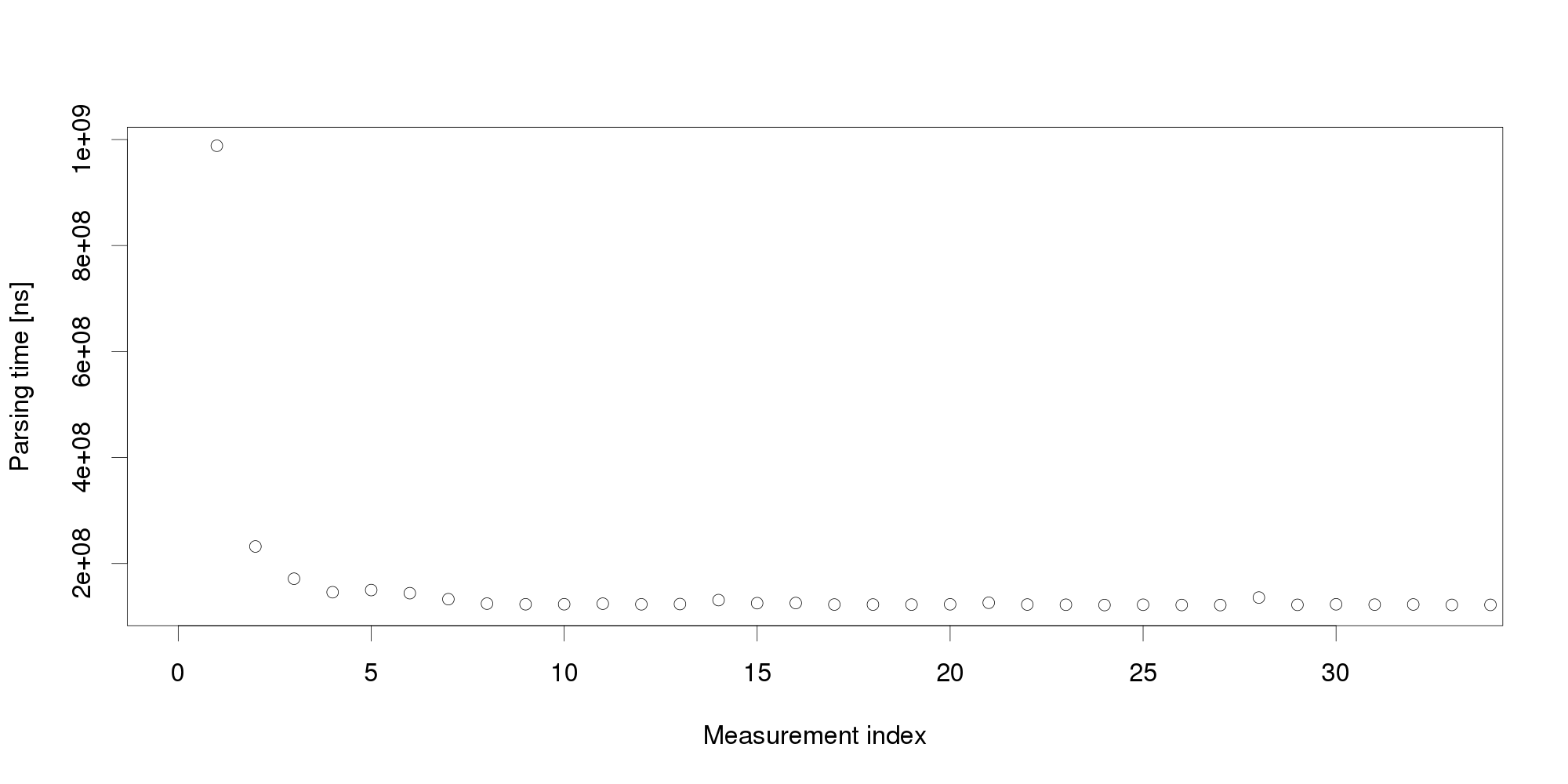
By looking at the graph, we can conclude that the measurements become stable after 5 observations. The remaining values differ very little and appear a suitable input for triggering adaptation. But collecting more measurements dispels this impression: Pursuing the same line of thought, we can conclude that performance is not as stable as we originally thought, and add even more measurements:
Pursuing the same line of thought, we can conclude that performance is not as stable as we originally thought, and add even more measurements: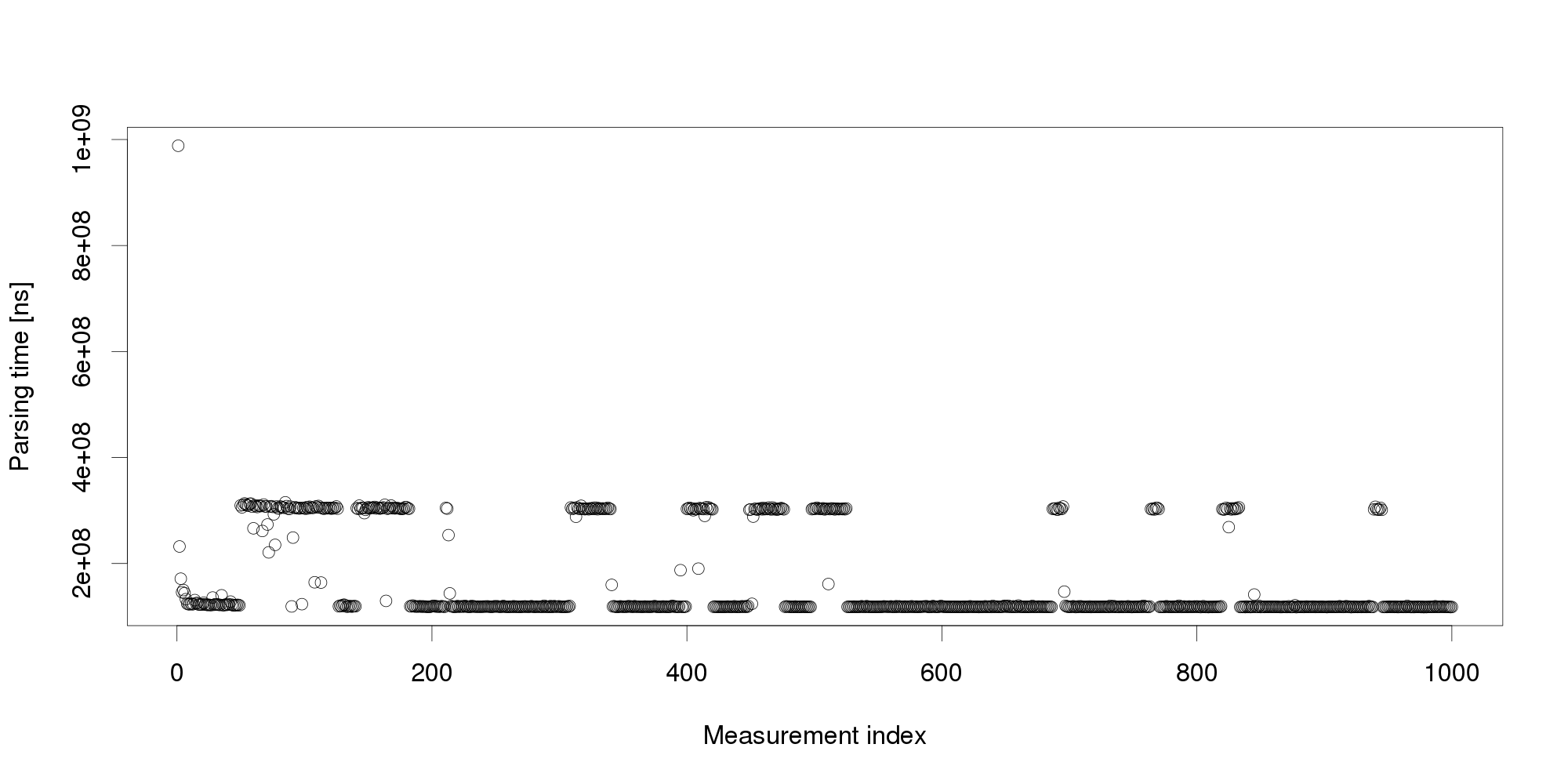 The graph shows that the change we have observed in the first 100 measurements is actually a common pattern. The XML processing server exhibits multiple performance modes that change at irregular intervals, and the processing time does not seem to stabilize in a reasonably short interval. More measurements after restart also show that the modes themselves are not necessarily stable:
The graph shows that the change we have observed in the first 100 measurements is actually a common pattern. The XML processing server exhibits multiple performance modes that change at irregular intervals, and the processing time does not seem to stabilize in a reasonably short interval. More measurements after restart also show that the modes themselves are not necessarily stable:
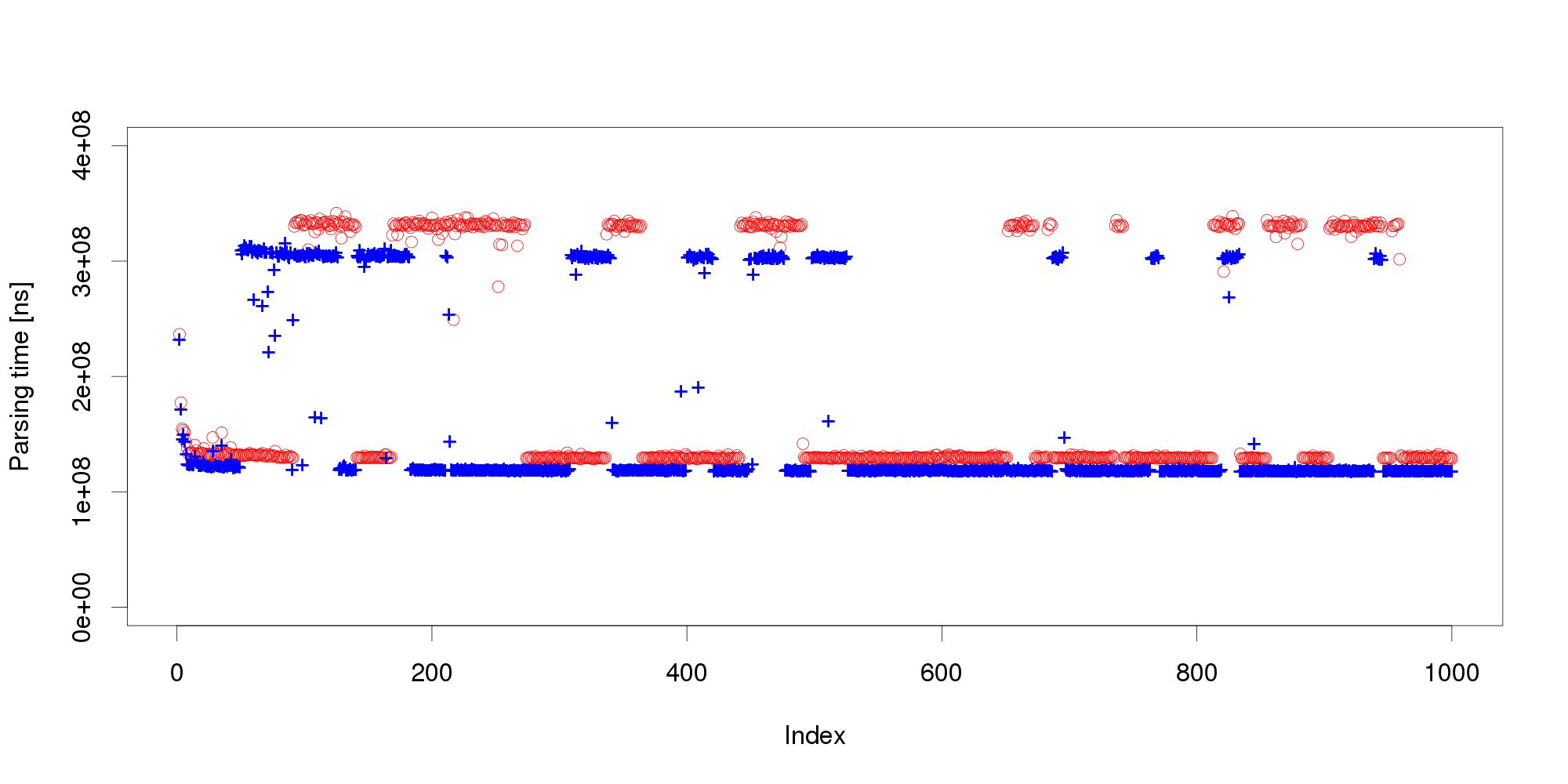
Experience indicates this is not an unusual behavior. On the contrary, similar behavior can be observed with many software systems, and is often made even worse by additional measurement noise (here, we have measured the data under very stable controlled conditions to demonstrate our point). Obviously, mere threshold detection is not useful to identify changes.
We address the issue with a novel non-parametric method that first learns what is an insignificant change to then detect the significant ones. The method bootstraps from historical data to compute the statistical properties of performance measurements under circumstances that do not require adaptation. Once this is done, the method requires only a few measurements to reliably detect whether they represent a significant performance change. To illustrate our results, we subject the XML processing server to a changing workload and use both our non-parametric method and Welch's t-test to detect changes in performance:
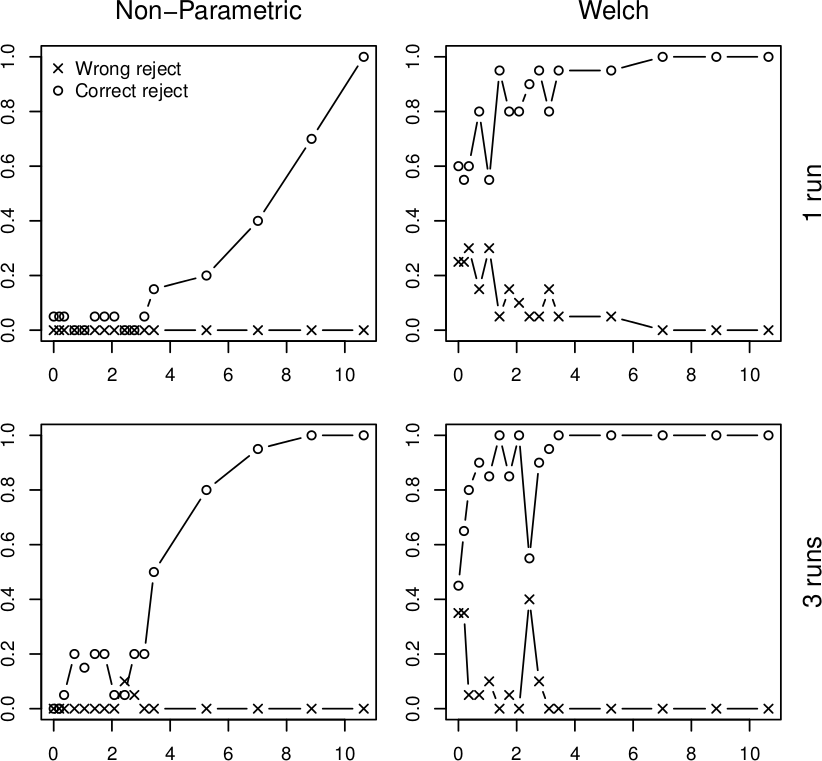
In all four graphs, the x axis shows the percentual change in workload size, the y axis gives the probability of detecting this change. The top row shows the detection after a single measurement, the bottom row does the same for three measurements. The "o" points mark correct change detections, the "x" points mark situations where the direction of the change was not detected correctly. We can see that in realistic conditions, the Welch's t-test would lead to frequent incorrect adaptation that our non-parametric method prevents. More details upon request (a publication is under review).
Vojtěch Horký
CUNI, Prague