Feedback Loops in the Development of Autonomic Systems
The development of autonomous systems goes beyond addressing the classical phases of the software development life cycle like requirements elicitation, implementation and deployment. Engineering autonomic systems has also to tackle aspects such as self-* properties like self-awareness and self-adaptation. Such properties have to be considered from the beginning of the development process, i.e. during elicitation of the requirements. We need to capture how the system should be adapted and how the system or environment should be observed in order to make adaptation possible.
Models are usually built on top of the elicited requirements, mainly following an iterative process, in which also validation and verification in early phases of the development are highly recommended, in order to mitigate the impact of design errors. A relevant issue is then the use of modeling and implementation techniques for adaptive and awareness features. Our aim is to focus on these distinguishing characteristics of autonomic systems along the whole development cycle.
We propose a “double-wheel” life cycle for autonomic systems to sketch the main aspects of the engineering process. The “first wheel” represents the design or offline phases and the second one represents the run-time or online phases.
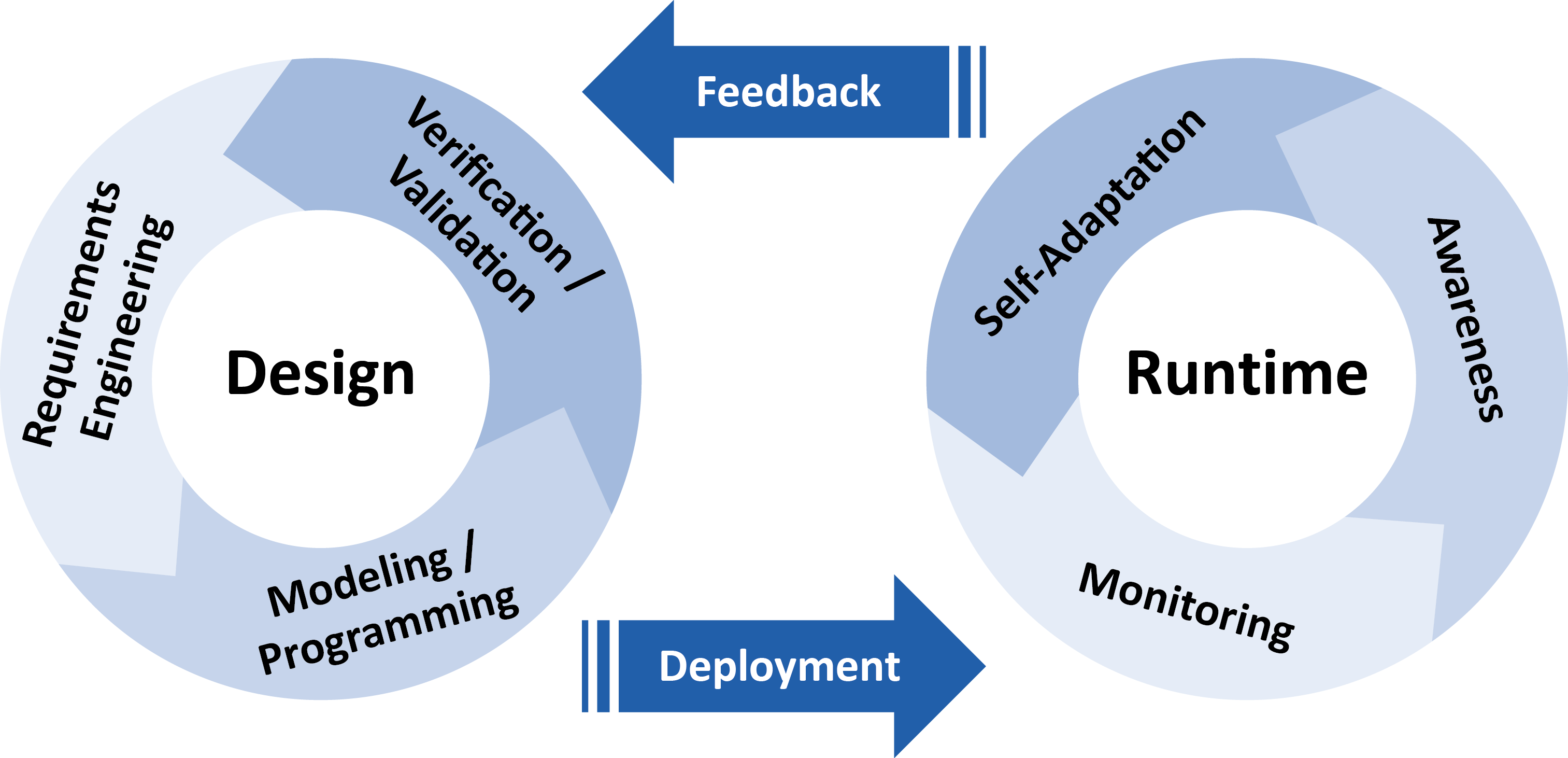
Both wheels are connected by the transitions deployment and feedback. The offline phases comprise requirements engineering, modeling and programming and verification and validation. We emphasize the relevance of mathematical approaches to validate and verify the properties of the autonomic system and enable the prediction of the behavior of such complex systems. This closes the cycle providing feedback for checking the requirements identified so far or improving the model or code. The online phases comprise monitoring, awareness and self-adaptation. They consist of observing the system and the environment, reasoning on such observations and using the results of the analysis for adapting the system and providing feedback for offline activities. Transitions between online and offline activities can be performed as often as needed throughout the system’s evolution, and data acquired during monitoring at runtime are fed back to the design cycle to provide information to be used for system redesign, verification and redeployment.
The process defined by this life cycle can be refined providing details on the involved stakeholders, the actions they perform as well as needed input and the output they produce. A process modeling languages can be used to specify the details. We can use therefore general workflow-oriented modeling languages such as UML activity diagrams2 or BPMN, or Domain Specific Languages (DSL) such as the OMG standard Software and Systems Process Engineering Metamodel (SPEM).
Within the ASCENS project several languages, methods and tools have been developed or previously existing ones have been extended to address engineering of ensembles. The development of a particular autonomic system will imply the selection of the most appropriate languages, methods and tools, i.e. an instantiation of the life cycle.
Can component policies be exploited by external reasoners?
In a scenario like the e-mobility one, e-vehicles should be equipped with reasoning units capable of dealing with unexpected events, like e.g., failure in booking a parking lot, traffic jams, or unavailability of booked parking lots. To react to these situations, appropriate actions should be determined and taken. We discuss the reasoning issue in the context of SCEL, a formal language developed to program autonomic computing systems in terms of the constituent components and their reciprocal interactions.
As shown in Figure 1, a SCEL autonomic component results from the interaction among knowledge and behavior components, according to specific policies. These provide a simple, yet expressive, linguistic tool for defining and enforcing rules to specify strategies, requirements, constraints, guidelines, etc. about the behaviour of systems and of their components.
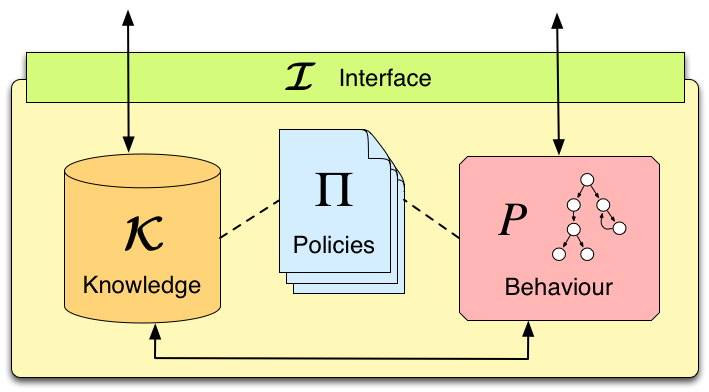
Figure 1: SCEL component
Policies may depend on the values of components' attributes (reflecting the status of components and their context) and can be dynamically modified for better reacting to system or environment changes. Moreover, as an effect of policy evaluation, specific actions, implementing adaptation strategies, can be produced at run-time and used to modify the behaviour of components.
Therefore, policies provide a simple form of self- and context-aware reasoning, supporting the achievement of self-* properties of the autonomic system. For example, when an e-vehicle is looking for available parking lots in nearby car parks, an internal policy could be used to ignore both parkings not equipped with charging station if the e-vehicle has a low battery level, and parkings with a cost per hour greater than a maximum cost established by the driver.
However, more sophisticated reasoning machineries can be necessary to deal with specific circumstances or when concerned with specific application domains. In these cases, separate reasoning units can be used by SCEL programs whenever decisions have to be taken.
Different reasoners, designed and optimised for specific purposes, can be exploited according to the components needs. Specifically, whenever SCEL systems have to take decisions, they have the possibility of invoking an external reasoner to receive informed suggestions about how to proceed. These answers would rely on the provided information about the relevant knowledge systems have access to and about their past behavior.
For example, in case of an unexpected event in the e-mobility scenario, a reasoner could be exploited by e-vehicles to dynamically re-plan their journey. Intuitively, the list of points-of-interest to be visited should be provided to the reasoner, which would shuffle it following some criteria, and would return the obtained list to the SCEL component that required it.
Figure 2 depicts such an enriched SCEL component, together with a generic external reasoner R. With respect to Figure 1, now local communications are filtered by a reasoner integrator RI (see post "Reasoning about reasoning agents").
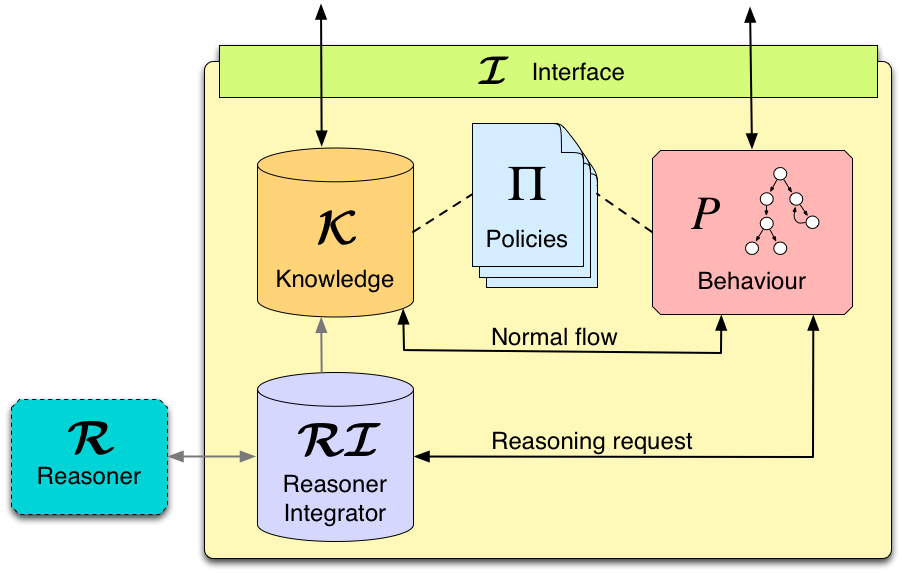
Figure 2: SCEL component with external reasoner
What we envisage is using policies not only for regulating components interaction, but also for managing the use of external reasoners. Policies could instruct the reasoners according to specific conditions on the internal status of the component and on external factors. For example, policies could urge the reasoner to return a solution as soon as possible, thus avoiding an exhaustive search. Moreover, policies could act as a filter for input data sent to the reasoner (e.g., sensible information about the driver could be removed from his profile before passing it to the reasoner), as well as for output data (e.g., actions returned by the reasoner could be blocked if they violate the e-vehicle polices). Anyway, as shown in Figure 3, how to reconcile policing and external reasoning is still an open issue.
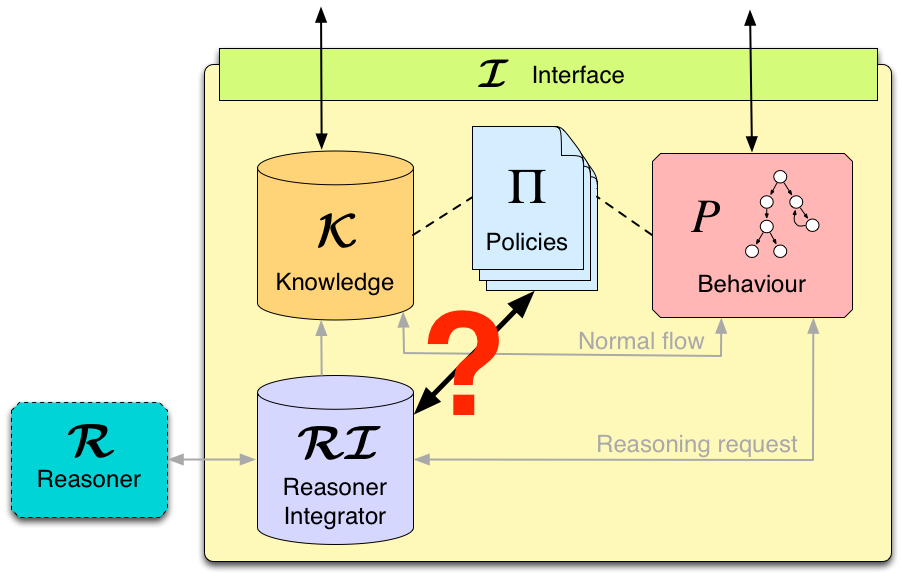
Figure 3: integration between policies and external reasoner
To tackle this issue, we should first be able to conceive under which conditions policies can help the reasoners, and to define appropriate interactions protocols between reasoners and policies handlers.
Rocco De Nicola and Francesco Tiezzi
IMT, Lucca
Is your software adaptive?
As business processes and software architectures have started to extend beyond the boundaries of corporate systems through the Internet, computing systems have been facing a complete new set of expectations as well as market opportunities. Not only there has been an increasing complexity to be met for guaranteeing that the offered networks and services are trustworthy, but the need of designing and implementing open, loosely coupled services has come together with rapidly changing requirements to be met, with severe time-to-market constraints to be met and with unpredictable service compositions to be anticipated. In principle, autonomic systems are the best answer to these challenges, because they are capable to self-adapt to changing scenarios. In practice, there is no common agreement in the literature on what makes a system be adaptive, so that autonomic systems can be engineered under completely different and possibly conflicting strategies and operating guidelines.
Self-adaptive systems have been widely studied in several disciplines ranging from Biology to Economy and Sociology and there it is widely accepted that a system is self-adaptive if it can modify its behaviour as a reaction to a change in its context (e.g., the environment, the knowledge accumulated). But the problem with such definition emerges during the translation to the Computer Science setting, because it becomes too ambiguous to be helpful in discriminating adaptive systems from non-adaptive ones. In fact, most programs can change behaviour (as they can execute conditional statements, handle exceptions, etc.) as a reaction to a change in their context (as they can input data, modify parameters, etc.). And then, must an adaptive system always be capable to react to any change? Or does it suffice that it may adapt to some changes? Typically the behaviour is changed to improve some measure of performance or degree of satisfaction, but there can be no warranty about that, so what if the opposite happens? Does a system that decreases its performance deserve to be called adaptive?
As an example, consider the scenario of a speaker at a meeting that wants to connect her notebook to the beamer for given her presentation. The software of the notebook and of the beamer has been designed separately, without knowing which kind of beamer (resp. notebook) will be connected to, an agreement must be found for choosing the resolution at which the beamer will work and it is maybe the case that the resolution of the screen of the laptop will change as a consequence. Given these premises, one is lead to conclude that beamer and the notebook are adaptive systems. But what if we are told that the beamer is controlled by a loop that tries to synch with the notebook, starting from the highest resolution to lower ones until a common resolution is found? Isn't this just a default behaviour? Would you still call the beamer adaptive? And the notebook?

As a more interesting example, take the swarms of robots studied in the ASCENS case studies and one of the many challenging adaptation scenarios, like the hill crossing one, where the robots must self-assemble
if they encounter a hill to steep to climb alone. Looking at one of the video demo is impressive: the robots try and fail several time until they finally succeed (or maybe some robots is left alone behind). There is little doubt in calling the software of the robots (self-)adaptive. Still, a closer look at the so-called basic self-assembling strategy they run reveal a finite state machine controlling the adaptation strategy, not much different than a few conditional statement in a program in the end.
Puzzled by the above examples and many similar ones, we have come to the conclusion that the main problem with definition given above is that it relies on a black box view of the system, where an observer tries to classify the system without looking at the software it runs. This is reasonable in many other fields where adaptive systems have been studied, like Biology, because we cannot have a direct look at the "software" and we need to guess it. But the assumption is no longer valid in software systems, especially when the designer perspective is taken, not the user one.
The ambiguity becomes less striking when we take a white boxview of the system. In fact, many architectural approaches to autonomic systems take radically different guidelines on the way they can be structured or composed and on the way they operate. However, in most cases, such approaches are prescriptive: they take an underlying principle and explain how to build autonomic system according to that principle. For example, in the FORMS approach (FOrmal Reference Model for Self-adaptation) reflection is taken as a necessary criterion for any self-adaptive system: roughly, it must be capable to represent and manipulate a meta-level description of itself / of its behaviour. In the MAPE-K approach a self-adaptive system is made of a component implementing the application logic, equipped with a control loop that Monitors the execution through sensors, Analyses the collected data, Plans an adaptation strategy, and finally Executes the adaptation of the managed component through effectors; all the phases of the control loop access a shared Knowledge repository. While FORMS and MAPE-K are not necessarily conflicting, they suggest diverging architectures: in the case of MAPE-K, a strictly hierarchical structure is recommended, where the application logic of one layer implements the adaptation logic of the layer below and the two are to be kept well separated; in the case of FORMS it is favoured a mixture of application logic and adaptation logic by the use of reflection at the level of the application logic.
In a recent work we have proposed an architecture-agnostic, conceptual framework for adaptation, where the white box view of the system is essential. The crux of the framework is that the decision of whether a system is adaptive or not is a relative matter, not an absolute one.
According to a traditional paradigm, a program governing the behaviour of a component is made of control and data : these are two conceptual ingredients that in presence of sufficient resources (like computing power, memory or sensors) determine the behaviour of the component. In order to introduce adaptivity in this framework, we require to make explicit the fact that the behaviour of a component depends on some well identified control data, without being prescriptive on the way it is marked as such. Then: we define adaptation just as the run-time modification of the control data; we say that a system is adaptive if its control data are modified at run-time, at least in some of its executions; and we say that a system is self-adaptive if it is able to modify its own control data at run-time.
Ideally, a sensible collection of control data should be chosen to enforce a separation of concerns, allowing to distinguish neatly, if possible, the activities relevant for adaptation (those that affect the control data) from those relevant for the application logic only (that should not modify the control data). Then, any computational model or programming language can be used to implement an adaptive system, just by identifying the part of the data governing the behaviour. Consequently, the nature of control data can greatly vary depending on the degree of adaptivity of the system and on the computational formalisms used to implement it. Examples of control data include configuration variables, rules (in rule-based programming), contexts (in context-oriented programming), interactions (in connector-centred approaches), policies (in policy-driven languages), aspects (in aspect-oriented languages), monads and effects (in functional languages), and even entire programs (in models of computation exhibiting higher-order or reflective features).
So, coming back to the question posed in the title of this post, if you need to decide if you software system is adaptive or not, you need to name your control data first, then the rest will follow.
Challenges of Engineer Autonomic Behaviors
A well recognized research challenge for future large-scale pervasive computing scenarios relates to the need of enforcing autonomic, self-managing and self-adaptive, behaviour, both at the level of the infrastructure and at that of its services.
Indeed, the increasing decentralization and dynamics of the current and emerging ICT scenarios (a variety of highly-distributed devices of an ephemeral and/or mobile nature, with users and developers capable of injecting new components and services at any time) make it impossible for developers and system managers to stay in the control loop and directly intervene in the system for configuration and maintenance activities (e.g., for configuring or personalizing new distributed devices or services, for fixing problems in existing devices and services, or for optimizing resource exploitation).
Accordingly, in the past few years, a large number of research proposals have been made, at both the infrastructural and service levels, to promote autonomic and adaptive behaviour in pervasive computing systems. However, in our opinion, most of the current proposals suffer from several limitations when dived in future scenarios.
First, a number of approaches propose “add-ons” to be integrated in existing frameworks as, e.g., in the case of those autonomic computing approach “à la IBM”, suggesting coupling sophisticated control loops to existing systems to support self-management. The result is often in an increased complexity of current frameworks, which definitely does not suit the characteristics and the need for lightness of pervasive scenarios.
Second, a number of other proposals suggest relying on light-weight and fully decentralized approaches, typically inspired by natural phenomena of self-organization and self-adaptation. However, most of these exploit the natural inspiration only for the implementation of specific algorithmic solutions or for realizing specific distributed services, either at the infrastructural or at the user level, rather than for attacking the issue of autonomic self-adaptation in a comprehensive way.
Third, and although an increasing number of researchers focuses on the social aspects of pervasive computing and on the provisioning of innovative social services, they do not properly account for the social level as an indistinguishable dimension of the overall pervasive computing fabric. That is, they do not account for the fact that users, other than simply consumers or producers of services, are de facto devices of the overall infrastructure, and contribute to it via human sensing, actuating, and computing capabilities, other than via an inherent strive for adaptation.
Based on the above considerations, our belief is that – rather than looking for one-of solutions to specific adaptation problems from specific limited viewpoints – there is need to deeply rethink the modelling and architecting of modern pervasive systems. As challenging as this can be, one should try to account in a foundational and holistic way for the overall complex needs of adaptation and autonomic behaviour of future pervasive computing systems. The final goal should be that of making such systems inherently capable of autonomic self-management and adaptation at the collective level, and having the distinction between infrastructural, services, and social levels, blur or vanish completely.
The achievement of the outlined broad goal calls for facing a number of specific challenging research issues, necessary to compose the global picture. These may include, among the others:
- Supporting Comprehensive Self-awareness. While the need for situation-awareness is already a recognized issue in pervasive computing, future scenarios will require autonomous adaptation activities to be driven by more comprehensive levels of awareness than traditionally enforced in context-aware computing models, where it is typically up to each component to access and digest the information it needs to take adaptation decisions. Such awareness models should encompass situations occurring at the many different levels of the system, as well as the strict locality of components, and be eventually able to provide components of the pervasive computing infrastructure with expressive and compact representations of complex multi-faceted situations, so as to effectively drive each and every activity of the components in a collectively coordinated way.
- Reconciling Top-Down vs Bottom Up Approaches. Along with the traditional “top-down” approaches to the engineering of pervasive computing systems, in which specific functionalities or behaviour are achieved by explicit design, “bottom-up” approaches are being proposed and adopted too (as we have already anticipated), to achieve functionalities via spontaneous self-organization, as it happens in natural systems. Most likely, both approaches will coexist in future pervasive computing scenarios, the former applied to the engineering of specific local functionalities, the latter applied to the engineering of large-scale behaviours (or simply emerge as a natural collective phenomena of the system). Thus, there will be need to understand the trade-offs between the power of top-down adaptation and bottom-up one, also by studying how the two approaches can coexist and possibly conflict in future systems, and possibly contributing in smoothing the tension between the two.
- Enforcing Decentralized Control. In large-scale systems, we should never forget that the existence and exploitation of phenomena of collective adaptation must necessarily come along with models and tools making it possible to control “by design” the overall behaviour of the pervasive systems and its sub-parts. Clearly, due to the inherent decentralization of the systems, such control tools too should make it possibly to direct the behaviours of the system in a decentralized way, and should be coupled by means to “measure” such behaviours in order to understand if the control is effective. The issue of defining sound measures for future pervasive computing scenarios can define in itself a challenging research area, given the size of the target scenario and the many – and often quite ill-defined – purposes it has to concurrently serve.
The need for laying out brand new foundations for the modelling and architecting of autonomic and self-adaptive pervasive computing systems, opens up a large number of fascinating and challenging research questions. In the ASCENS project, we are trying to understand how it is possible to identify a sound set of self-aware adaptation patterns for ensemble, and how such patterns can be used for engineering both top-down and bottom-up adaptation schemes, other than for enforcing in a decentralized way control over the global behaviour of ensembles.
In any case, the short list of challenges that we have provided above and that we are currently tackling in ASCENS is far from being exhaustive. For instance, it does not account for the many inter-disciplinary issues that the understanding of large-scale socio-technical organisms (as future pervasive computing systems will be) and their collective adaptive behaviours involve , calling from exploiting the modern lessons of applied psychology, sociology, social anthropology, and macro-economy, other than those of systemic biology, ecology and complexity science. Plenty of room for additional projects to complement ASCENS!
ASCENS in Quest of Awareness-Rich Technology
The ASCENS project aims at bringing awareness into technical systems. Formalisms, linguistic constructs and programming tools should be developed featuring high level of autonomous and adaptive behavior. Rigorous and sound concepts will be used to reason and prove system properties, but how can we judge the project’s pragmatic significance? The impact and practical value of the ASCENS project results will be evaluated on e-mobility, cloud computing and swarm robotics application domains. The three novel application domains look complex and fairly different and one may ask: isn’t each problem difficult enough? Why solving all three at once?
1. What E-mobility, Cloud Computing and Swarm of Robots Have in Common?
E-mobility is a vision of future transportation by means of electric vehicles network allowing people to fulfill their individual mobility needs in an environmental friendly manner.
Cloud computing is an approach that delivers computing (resources) to users in a service-based manner, over the internet.
Swarm robotics deals with creation of multi-robot systems that through interaction among participating robots and their environment can accomplish a common goal, which would be impossible to achieve by a single robot.
At a first glance e-cars and transportation, distributed computing on demand and swarm robotics have nothing in common!
1.1 Sharing and Collectiveness
In order to cover longer distances, an e-vehicle driver must interrupt the journey to either exchange or re-charge the battery. Energy consumption has been the major obstacle in a wider use of e-vehicles. Alternative strategy is to share e-vehicles in a way that optimizes the overall mobility of people and the spending of energy. In other words: when my battery is empty – you will take me further if we go towards the same location and vice versa.
The processing statistics show that most of the time computers are idle – waiting for input to do some calculations. Computers belong amongst fastest and at the same time most wasted devices man has ever made. And they dissipate energy too. Cloud computing overcomes that problem by sharing computer resources and making them better utilized. In another words if my computer is free – it can process your data and vice versa; or even better, let us have light devices and leave a heavy work for the cloud.
A swarm indicates a great number of things in motion. Swarm robots dynamically form different shapes in order to solve a collective assignment. Swarm of robots can perform much more as a group than any single element can do on its own. In other words, what we cannot achieve alone, we may manage together.
At a closer look “sharing and collectiveness” are common characteristics of all three application domains!
1.2 Awareness and Knowledge
E-mobility can support coordination only if e-vehicles know their own restrictions (battery state), destinations of users, re-charging possibilities, parking availabilities, the state of other e-vehicles nearby. With such knowledge collective behavior may take place, respecting individual goals, energy consumption and environmental requirements.
Cloud computing deals with dynamic (re-)scheduling of available (not fully used) computing resources. Maximal utilization can only be achieved if the cloud is “aware” of the users’ processing needs and the states of the deployed cloud resources. Only with such a knowledge a cloud can make a good utilization of computers while serving individual users needs.
Each robot in a swarm needs to know its own and the others’ location and capabilities as well as an overall assignment. Only then a swarm can achieve the common goal.
At a closer look “awareness” of own potentials, restrictions and goals as well as those of the others is a common characteristic. All three domains require self-aware, self-expressive and self-adaptive behavior.
1.3 Dynamic and Distributed Optimization
E-mobility is a distributed network that manages numerous independent and separate entities such as e-vehicles, parking slots, re-charge stations, drivers. Through collective and awareness-rich control strategy the system may dynamically re-organize and optimize the use of energy while satisfying users’ transportation needs.
Cloud computing actually behaves as a classical distributed operating system with a goal to maximize operation and throughput and minimize energy consumption, performing tasks of multiple users.
Swarm robotics deals with coordination of a collection of individual robots in order to optimize control strategy through interaction among the robots and the environment.
At a closer look “dynamic and distributed optimization” is inherent characteristic of the control environment for all three application domains.
2. Again, What E-mobility, Cloud Computing and Swarm of Robots Have in Common?
Control systems for all the three domains have many common characteristics: they are highly collective, constructed of numerous independent entities that share common goals. Their elements are both autonomous and cooperative featuring a high level of self awareness and self expressiveness. A complex control system built out of such entities must be robust and adaptive offering maximal utilization with minimal energy and resource use.
3. What the three domains have to do with ASCENS Project?
Formal definition, programming and controlling of complex massively parallel distributed system that feature awareness, autonomous and collective behavior, adaptive optimization and robust functioning are grand challenges of computer science. These challenges are present in most of complex control systems and they are the motivation and inspiration for the ASCENS project. The consortium gathered scientists from different fields in effort to offer novel and scientifically sound concepts and approaches:
- SCE - service–component ensembles as means to dynamically structure independent and distributed system entities
- Modeling and formalization of the fundamental SCE properties as means to rigorously reason about autonomous behavior and aware-rich networking, proving that important system requirements hold
- linguistic support for programming SCEs, expressing awareness and exchanging knowledge among system entities
- adaptive and knowledge-rich software environments and tools, expressing and deploying self-awareness and self-expression in technical systems
(see the ASCENS project goal [http://www.ascens-ist.eu/]). Consequently three different application domains are selected to test the pragmatic significance of the envisaged project concepts and results.
4. What should be the impact of ASCENS Solutions?
The ASCENS project calls for a new generation of technical solutions (techno-sphere) that would be better integrated into our biosphere by mimicking some natural phenomena like awareness, swarm behavior and adaptation. The ultimate rationale is: our resources are not endless thus our technical innovations need to be optimized and self- and energy-aware. We cannot for ever allow ourselves a luxury of driving own cars (on a global earth with increasing population and decreasing energy resources); we cannot for ever allow ourselves the luxury of switching on powerful computers that waste energy without doing much processing. We cannot neglect the usefulness of a swarm behavior (so much present in the nature) that teaches us how simple element can perform complex endeavor in a collective effort. The nature obviously achieves perfection through simplicity. Can we mimic that?
As you do not buy a cow when you need milk, you do not need to possess a car if you want to have free mobility; you do not require a powerful computer if you have processing necessities, you do not need a complex robot if you want automatic assistant. We should be oriented to hire and be charged per use rather than to buy and possess things as this may be a proper way to optimize the use of our precious resources.
To make such a mental and behavioral transition we need better control systems. We hope the ASCENS approach with its generic solutions for a wide class of applications, is a grand step in this direction.
Why is it useful to describe e-mobility using service component ensembles (SCE)?
Own Car versus Mobility Service
In a future e-mobility-scenario, it is assumed that many people don’t have their own cars. They will use vehicles temporally depending on their mobility needs. Why this assumption?
There are many of reasons for this development. All of these reasons are closely related to energy constraints and hence to the battery. The limited capacity of the battery leads to range limitation. The necessary charging time reduces the e-car availability. The high battery cost makes the car expensive and the life cycle of battery limits the time value of the vehicle. Through these arguments it can be seen that user will value mobility more than the e-vehicles itself.
Temporal Composition of Service Component Ensembles

From this point of view it is interesting to apply flexible service architectures for supporting the user. The scenario components “user” (blue colored in the figure) and “vehicle” (green colored) are no longer strongly connected in this e-mobility scenario. The scenario components are represented by their service components, which are acting as components in the user-vehicle-infrastructure network. All service component types are temporally connected for trips or sequences of trips (journeys). Additional infrastructure service components (yellow colored) assist by searching charging stations or route planning. In this view trips (A, B, C) in a journey are the constructors of service component ensembles (SCE).
What are Ensembles? And Why Should I Care?
Our goal in ASCENS is to build "Autonomic Service-Component Ensembles"—sounds nifty (or so we thought), but what does it actually mean?
A Little Bit of History
The meaning for "ensemble" that we use in ASCENS was coined in the InterLink project's work group on software-intensive systems and new computing paradigms, somewhere around 2007. In this group we all agreed that many systems that we will be building in the next decades will share a number of important properties. But none of the terms in current use—software-intensive systems, cyber-physical systems, etc.—seemed to really differentiate the entities we were talking about from those we were not particularly interested in. At some point Seth Goldstein suggested the name "ensembles" for the kinds of complex, networked cyber-physical systems we were discussing and it proved to be an instant hit in our group. When writing up the report for our workshop I needed a word for "ensembles which are not cyber-physical systems", so I hijacked Seth's term for this more general concept and used physical ensembles for the original meaning.
Well, then, the million dollar question is:
What are Ensembles?
Glad you asked. Ensembles are software-intensive systems with massive numbers of nodes or complex interactions between nodes, operating in open and non-deterministic environments in which they have to interact with humans or other software-intensive systems in elaborate ways. Ensembles have to dynamically adapt to new requirements, technologies or environmental conditions without redeployment and without interruption of the system’s functionality, thereby blurring the distinction between design-time and run-time.
More catchy but less precise: ensembles are these systems where we currently know neither how to specify them nor how to build them. Wait a moment—there are systems that satisfy the definition of ensembles that have successfully been built. What about Google's infrastructure? What about the German LKW-Maut system?
The Good, the Bad, and the Lucky
Google's services definitely can be considered as an ensemble, and in fact cloud computing is one of the case studies in ASCENS. Why do we then claim that we don't know how to build ensembles? Well, Google's infrastructure, consisting of several clusters with hundreds of thousands or even millions of servers, is massive any way you look at it. But it is mostly used to scale (more or less) well-understood tasks with simple user interactions to unimaginably large data sets and numbers of transactions. Google as well as other "internet-scale" companies had to come up with clever solutions to overcome scalability problems, and this is probably one area of ensemble engineering where we will see a lot more progress in the future. But still, leaving aside the algorithmic problems of search, the problem of dealing with huge amounts of data, and some other trivialities (and thereby ignoring everything that makes Google tick...) the basic problem a search engine faces is building an index and looking up keywords in this index. So, yes, it is actually possible to build ensembles, at least for some of the simpler scenarios. If you want to be successful with that, it's probably a good idea to follow in Google's footsteps and focus on ensembles where the main problems are algorithms and scalability. And to hire some of the brightest minds in computer science to do it. It doesn't hurt to build better web interfaces than anybody else and to revolutionize our understanding of what web apps make possible, as they did with Google maps. And to generally do no evil.
Easy as pie. But just in case you weren't planning on following these steps, take care. Things can blow up in your face real quick.
Let's look at the German LKW-Maut system, the automated billing for truck's usage of motorways. The one good thing that can be said about that project is that it was finally completed. But it's not the kind of project you want to base your career on: The tender was accepted on September 20, 2002 with an expected completion date of August 31, 2003, one year later. After many troubles and changes in consortium management, the system started in a limited manner on January 1, 2005 and reached its full capabilities on January 1, 2006—more than 3 years after it started—with billions of Euros lost in expected revenue and with liquidated damages of 1.6 billion Euros. While this is a somewhat extreme example, large delays, cost overruns and systems that fulfill only a part of their original requirements are not at all uncommon when we try to build complex software systems using current development methods.
So the question is: How can we find reliable ways to build these kinds of systems? And what's the best way to build ensembles so that we can have confidence that they actually do what we want them to do?
And there is more: Google and the LKW-Maut system both work in relatively well-known environments with slowly changing requirements and infrastructure. What happens when you change to more dynamic scenarios? For example, what if you wanted to dynamically distribute the joint computing power of several universities to research projects in a "research grid"? How can we ensure that the distribution is fair to everybody involved? How do we deal with parts of the research grid suddenly becoming unavailable because of network problems or a power outage? What if the part that failed was the master node of a map-reduce operation? How do we discourage free riders that use too many resources of others without contributing anything of their own? How do we ensure that confidential data is only processed on authorized nodes?
These are fascinating questions, and we're lucky to be funded to investigate them in ASCENS. Stay tuned as we'll report on our progress.