On Detecting Significant Changes In Performance
Embedded in the very nature of adaptive systems is the ability to react to change - whenever there is a significant change in the parameters of the system or the surrounding environment, an adaptation is triggered. Common performance parameters, such as throughput or latency, are often among the triggers - however, deciding whether the observed change in performance is significant enough to warrant an adaptation is not an easy task.
To illustrate the difficulties, consider the ASCENS Cloud Case Study. A cloud application would often exhibit decreasing performance when faced with excessive workload - and an adaptive cloud application would react to this situation by allocating more processing capacity from the cloud. We pick one such application - an example XML processing server - and look at how such reactive adaptation works.
Our adaptation mechanism measures the request processing time and when the time exceeds a threshold, it launches a new XML processing server instance. From early testing, we know that the server should exhibit an average request processing time of around 100 ms. We use this average plus some slack to set the threshold - but when we deploy the application, the very first request processing time we collect is over 900 ms, well above even a very liberal threshold!
Obviously, the very first request cannot represent an excessive workload. We therefore turn to another obvious explanation, declaring the initial measurement distorted and therefore invalid. It is common to collect multiple measurements to filter out distortions, however, we cannot wait for too many measurements because that would increase the reaction time. We start with 30 measurements: 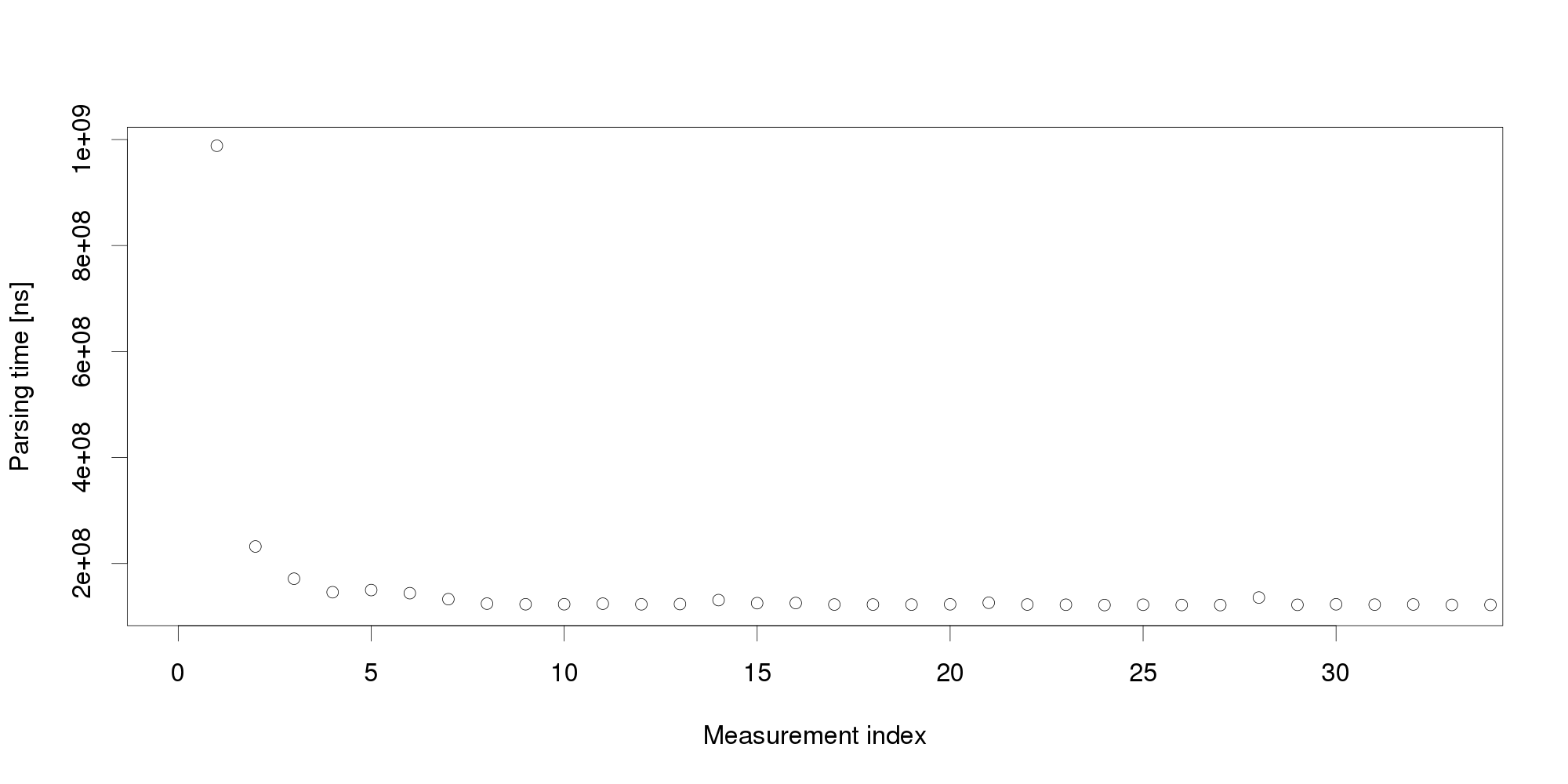
By looking at the graph, we can conclude that the measurements become stable after 5 observations. The remaining values differ very little and appear a suitable input for triggering adaptation. But collecting more measurements dispels this impression: Pursuing the same line of thought, we can conclude that performance is not as stable as we originally thought, and add even more measurements:
Pursuing the same line of thought, we can conclude that performance is not as stable as we originally thought, and add even more measurements: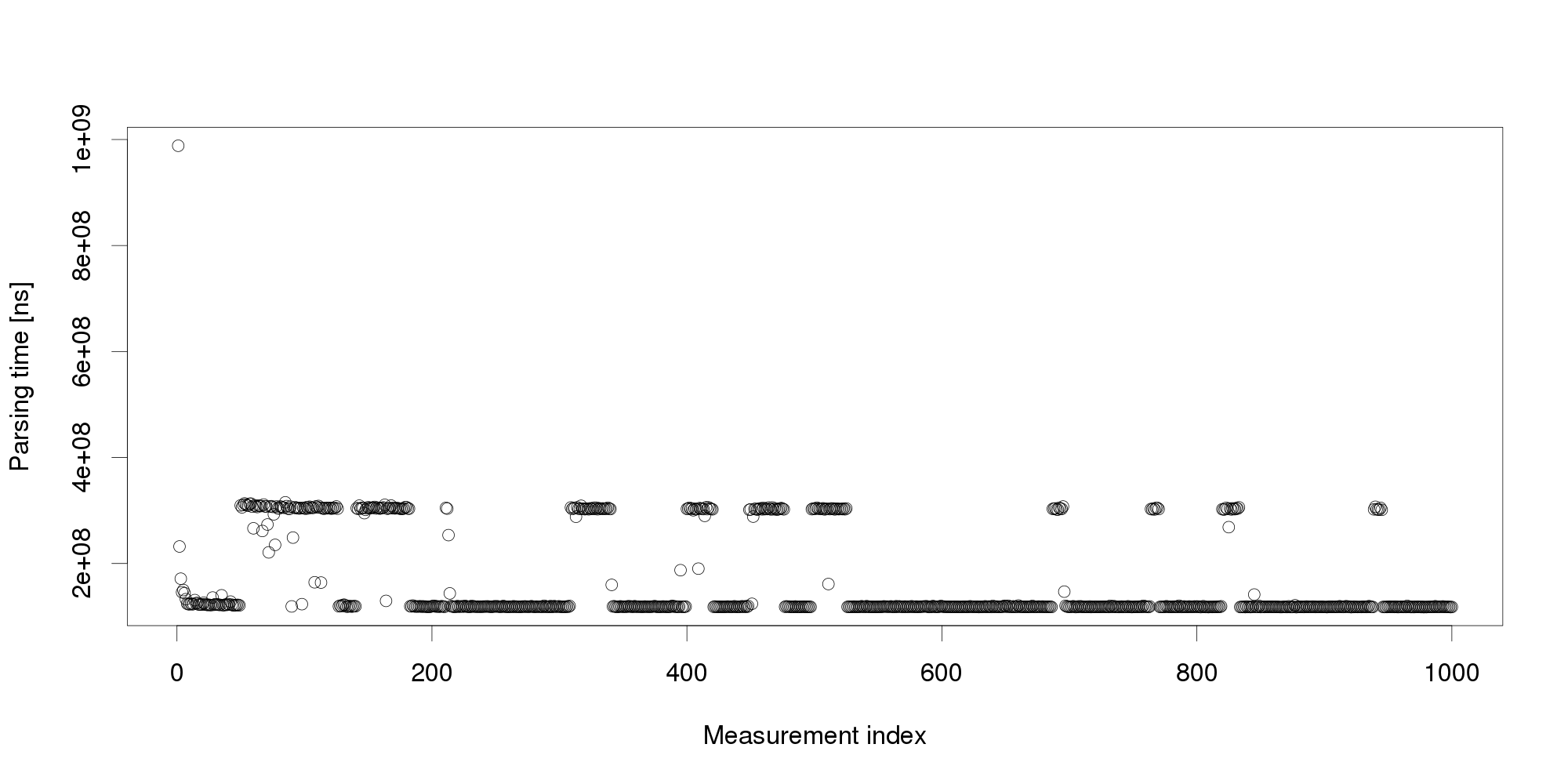 The graph shows that the change we have observed in the first 100 measurements is actually a common pattern. The XML processing server exhibits multiple performance modes that change at irregular intervals, and the processing time does not seem to stabilize in a reasonably short interval. More measurements after restart also show that the modes themselves are not necessarily stable:
The graph shows that the change we have observed in the first 100 measurements is actually a common pattern. The XML processing server exhibits multiple performance modes that change at irregular intervals, and the processing time does not seem to stabilize in a reasonably short interval. More measurements after restart also show that the modes themselves are not necessarily stable:
Experience indicates this is not an unusual behavior. On the contrary, similar behavior can be observed with many software systems, and is often made even worse by additional measurement noise (here, we have measured the data under very stable controlled conditions to demonstrate our point). Obviously, mere threshold detection is not useful to identify changes.
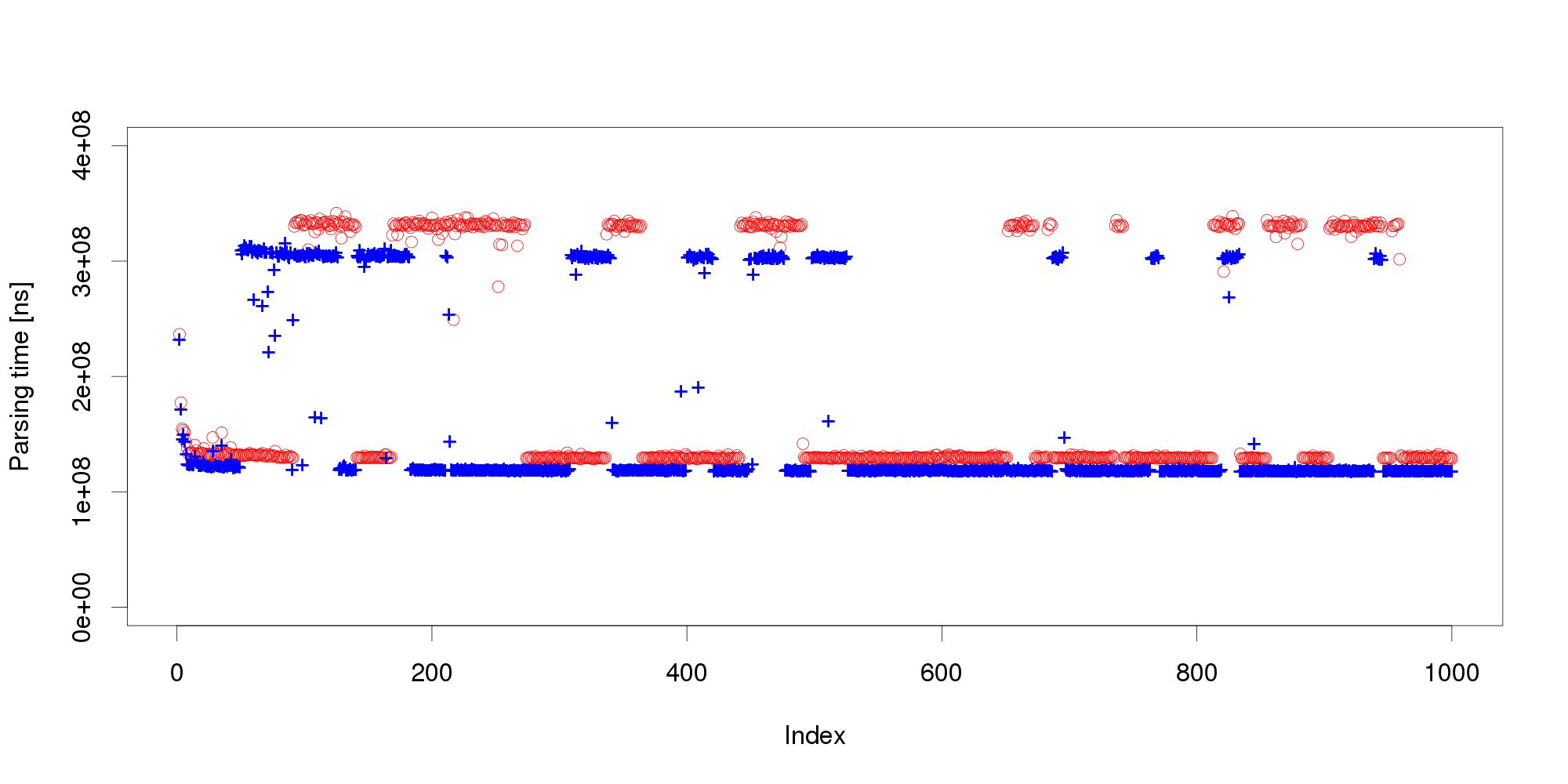
We address the issue with a novel non-parametric method that first learns what is an insignificant change to then detect the significant ones. The method bootstraps from historical data to compute the statistical properties of performance measurements under circumstances that do not require adaptation. Once this is done, the method requires only a few measurements to reliably detect whether they represent a significant performance change. To illustrate our results, we subject the XML processing server to a changing workload and use both our non-parametric method and Welch's t-test to detect changes in performance:
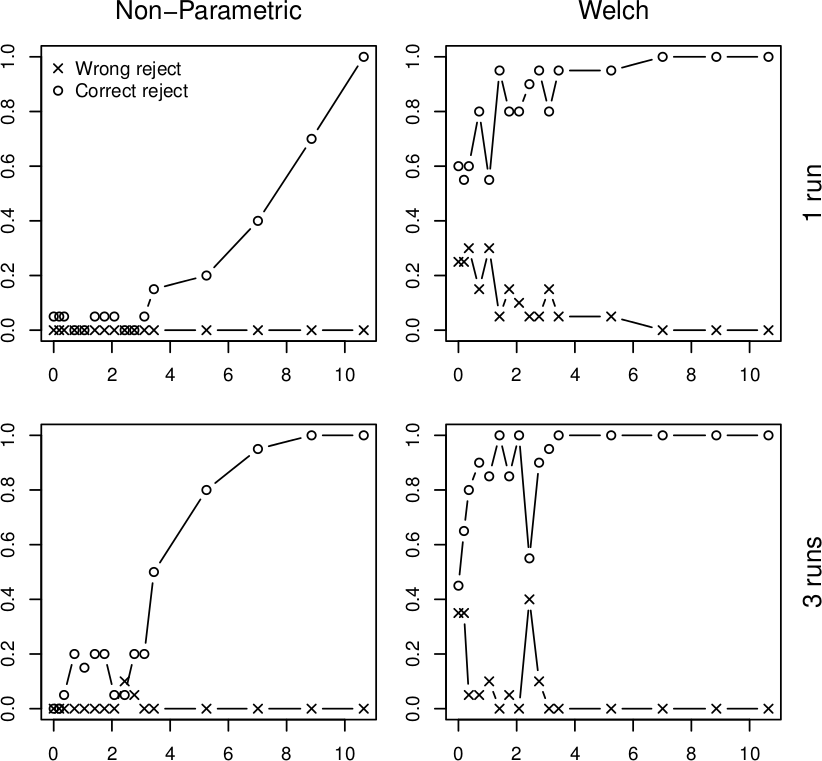
In all four graphs, the x axis shows the percentual change in workload size, the y axis gives the probability of detecting this change. The top row shows the detection after a single measurement, the bottom row does the same for three measurements. The "o" points mark correct change detections, the "x" points mark situations where the direction of the change was not detected correctly. We can see that in realistic conditions, the Welch's t-test would lead to frequent incorrect adaptation that our non-parametric method prevents. More details upon request (a publication is under review).
Vojtěch Horký
CUNI, Prague
Statistical Model-Checking
Computer systems play a central role in modern societies and their errors can have dramatic consequences. For example, such errors could jeopardize a banking system, possibly stalling the economy of a whole country or, more dramatically, endanger human life through the failure of some safety critical systems (railway signing, integrated avionics, air-traffic, medical life support machines, automotive electronics). It is therefore not surprising that proving the correctness of computer systems is a highly relevant problem. Unfortunately, the growing complexity in system design makes it almost impossible to ensure correctness simply by looking at the (possibly distributed) code. Automatic techniques are thus needed.
The most common method to ensure the correctness of a system is testing (see [3] for a survey). After the computer system is constructed, it is tested using a number of test cases with predicted outcomes. Testing techniques have shown effectiveness in bug hunting in many industrial applications. Unfortunately, testing is not a panacea. Indeed, since there is, in general, no way for a finite set of test cases to cover all possible scenarios, errors may remain undetected. There are also methods that can ensure the full correctness of a system. Those methods, also called formal methods, use mathematical techniques to check whether the system will behave correctly for all possible scenarios. Over the past, formal methods such as symbolic model checking [13] have been used to verify systems with more than 10^20 reachable states [4].
In an ideal world, it would thus be ``better'' to use formal methods rather than testing. Unfortunately, improvements in the development of formal methods do not seem to follow the increasing complexity in system design. Nowadays, most of formal methods suffer from the so-called state-space explosion problem, which makes them unusable for large industrial size applications. As testing does not suffer from the same problem, it remains the only scalable technique and is thus the one promoted by the industrials.
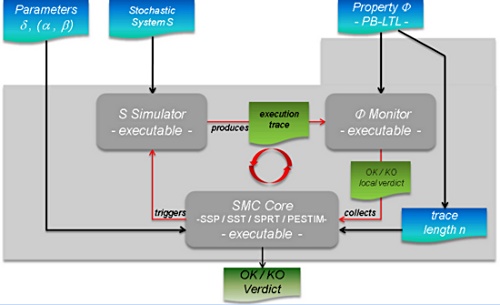
Statistical Model-Checking
As we already said, the major drawback with testing is that, in general, it does not give any confidence on the correctness of the entire system. This lack of accuracy has motivated the development of new algorithms that combine testing techniques with algorithms coming from the statistical area. Those techniques, also called Statistical Model Checking techniques (SMC) [9, 15], can be seen as a trade-off between testing and formal verification. In fact, SMC is very similar to Monte Carlo used in industry, but it relies on a formal model of the system. The core idea of SMC is to monitor a number of simulations of a system whose behaviors depend on a stochastic semantic. Then, one uses the results of statistics (e.g. sequential hypothesis testing or Monte Carlo) together with the simulations to get an overall estimate of the probability that the system will behave in some manner. While the idea resembles the one of classical Monte Carlo simulation, it is based on a formal semantic of systems that allows us to reason on very complex behavioral properties of systems (hence the terminology). This includes classical reachability property such as ``can I reach such a state ?'', but also non trivial properties such as ``can I reach this state x times in less than y units of time ?''. Of course, in contrast with an exhaustive approach, such a simulation-based solution does not guarantee a result with 100% confidence. However, it is possible to bound the probability of making an error. Simulation-based methods are known to be far less memory and time intensive than exhaustive ones, and are sometimes the only option [10].
Statistical model checking is widely accepted in various research areas such as software engineering, in particular for industrial applications [1, 12, 7], or even for solving problems originating from systems biology [6, 11]. There are several reasons for this success. First, SMC is very simple to understand, implement, and use. Second, it does not require extra modeling or specification effort, but simply an operational model of the system that can be simulated and checked against state-based properties. Third, it allows us to verify properties [5, 1] that cannot be expressed in classical temporal logics. Finally, SMC allows to approximate undecidable problems. This latter observation is crucial. Indeed most of emerging problems such as energy consumption are undecidable [8, 2] and can hence only be estimated.
Saddek Bensalem
Verimag
[1] Ananda Basu, Saddek Bensalem, Marius Bozga, Benoit Caillaud, Benoit Delahaye, Axel Legay. Statistical Abstraction and Model-Checking of Large Heterogeneous Systems. In FMOODS/FORTE, 2010.
[2] P. Bouyer, U. Fahrenberg, K. G. Larsen, and N. Markey. Timed automata with observers under energy constraints. In HSCC, pages 61-70. ACM ACM, 2010.
[3] M. Broy, B. Jonsson, J.-P. Katoen, M. Leucker, and A. Pretschner, editors. Model-Based Testing of Reactive Systems, Advanced Lectures The volume is the outcome of a research seminar that was held in Schloss Dagstuhl in January 2004, volume 3472 of Lecture Notes in Computer Science. Springer, 2005.
[4] J. R. Burch, E. M. Clarke, K. L. McMillan, D. L. Dill, and L. J. Hwang. Symbolic model checking : 1020 states and beyond. Information and Computation, 98(2) :142-170, 1992.
[5] E. M. Clarke, A. Donzé, and A. Legay. Statistical model checking of mixed-analog circuits with an application to a third order delta-sigma modulator. In Proc. of 3rd Haifa Verification Conference (HVC), volume 5394 of LNCS, pages 149-163. Springer, 2008.
[6] E. M. Clarke, J. R. Faeder, C. J. Langmead, L. A. Harris, S. K. Jha, and A. Legay. Statistical model checking in biolab : Applications to the automated analysis of t-cell receptor signaling pathway. In CMSB, volume 5307 of LNCS, pages 231-250. Springer, 2008.
[7] E. M. Clarke and P. Zuliani. Statistical model checking for cyber-physical systems. In ATVA, volume 6996 of Lecture Notes in Computer Science, pages 1-12. Springer, 2011.
[8] U. Fahrenberg, L. Juhl, K. G. Larsen, and J. Srba. Energy games in multiweighted automata. In ICTAC, volume 6916 of Lecture Notes in Computer Science, pages 95-115. Springer, 2011.
[9] T. Hérault, R. Lassaigne, F. Magniette, and S. Peyronnet. Approximate probabilistic model checking. In Proc. of 5th Int. Conference on Verification, Model Checking, and Abstract Interpretation (VMCAI), volume 2937 of LNCS, pages 73-84. Springer, 2004.
[10] D. N. Jansen, J.-P. Katoen, M.Oldenkamp, M. Stoelinga, and I. S. Zapreev. How fast and fat is your probabilistic model checker? an experimental performance comparison. In HVC, volume 4899 of LNCS. Springer, 2007.
[11] S. K. Jha, E. M. Clarke, C. J. Langmead, A. Legay, A. Platzer, and P. Zuliani. A bayesian approach to model checking biological systems. In Proc. 7th Int. Computational Methods in Systems Biology, 7th Int. conference (CMSB), volume 5688 of LNCS, pages 218-234. Springer, 2009.
[12] J. Martins, A. Platzer, and J. Leite. Statistical model checking for distributed probabilistic-control hybrid automata with smart grid applications. In ICFEM, volume 6991 of Lecture Notes in Computer Science, pages 131-146. Springer, 2011.
[13] K. McMillan. Symbolic Model Checking. PhD thesis, Carnegie Mellon University,
1993.
[14] K. Sen, M. Viswanathan, and G. Agha. Statistical model checking of black-box probabilistic systems. In Proc. of 16th Int. Conference on Computer Aided Verication (CAV), LNCS 3114, pages 202-215. Springer, 2004.
[15] H. L. S. Younes. Verication and Planning for Stochastic Processes with Asynchronous Events. PhD thesis, Carnegie Mellon, 2005.
Design of ensembles with the most beautiful woman in the world
The vision of autonomic computing drives the development of cutting-edge software systems. We no longer want to create systems which are thoroughly administrated by hand. Once employed, the system should rather manage itself, keep itself alive and running. At the same time, ubiquitous computing and global interconnectedness introduce more and more nodes into our systems. They become highly distributed and need to operate in diverse and changing environments. Those systems challenge us to think of designs for autonomic systems with large numbers of possibly heterogeneous nodes. They may collaborate in many concurrently running ensembles, each fulfilling its global goal despite unforeseen and changing conditions. Their complex interaction behavior needs to be designed carefully while at the same time it must be equipped with flexible mechanisms to dynamically adapt to evolving environments. Well-known techniques, like component-based software engineering, are not sufficient for modeling such systems, but must be augmented with other features that allow to focus on the particular characteristic of ensembles.
In the HELENA approach [1], we propose a modeling technique for ensembles centered around the notion of roles. Ensembles are built on top of a component-based platform as goal-oriented communication groups of components. The functionality of each group is described in terms of roles which a component may dynamically adopt. Therefore, components can freely join and leave ensembles without breaking the overall functionality of the collaboration as long as another component takes over the abandoned role. Components also dynamically adapt to new situations by changing their roles or by concurrently playing several roles (maybe in different ensembles) at the same time. Hence, the conceptual key point of HELENA is that in a system several ensembles can be established in parallel with each participating component playing (possibly) different roles in different collaborations at the same time.
The following figure shows such an ensemble in graphical notation. The underlying component-based platform is a peer-to-peer network storing files where this ensemble is dynamically formed to retrieve a file from the network. To perform this task, we envision three roles: requester, router, and provider. The requester wants to download the file. First it needs to request the address of the peer storing the file from the network, while using the routers as forwarding peers of its request. Once the requester knows the address, it directly requests the file from the provider for download. Each role can be adopted by peer component instances, but offers different capabilities to take over responsibility for the transfer task, e.g. the request must be able to request the address of the provider from a router while the router must be able to receive the request.

An important characteristic of ensemble-based systems is that components are aware of their environment and adapt their behavior accordingly. HELENA is well suited to conceptualize an adequate architecture for such systems. We require each component to adopt a distinctive role which is responsible for monitoring the environment and making the component aware of significant changes. By changing old roles into new ones the component can adaptively react to these observations.
HELENA allows rigorous ensemble modeling based on a solid formal foundation. We define the architecture of communication groups as ensemble structures composed of roles and role connectors and enhance them to ensemble specifications by adding role behaviors. The formal semantics of an ensemble specification introduces an execution model which is given by an ensemble automaton. The states of an ensemble automaton describe which role instances currently exist and which component instances currently adopt which roles. An ensemble evolves over time by message exchange between collaborating roles or by performing management operations like creating new role instance.
For the execution of ensemble-based systems, we provide the Java framework jHELENA [2] which transfers the role concept to object-oriented programming and follows the rigorous semantics of HELENA models. HELENA models can be described either graphically in a UML-like notation or in a domain-specific language fully integrated into the Eclipse Development Environment [3]. A code generator transforms those models to jHELENA code for execution.
Annabelle Klarl
LMU
[1] Rolf Hennicker, Annabelle Klarl. Foundations of Ensemble Modeling - The Helena Approach. Specification, Algebra, and Software. 8373, 2014, Vol. Lecture Notes in Computer Science, pp. 359-381.
[2] Annabelle Klarl, Rolf Hennicker. Design and Implementation of Dynamically Evolving Ensembles with the Helena Framework. [ed.] IEEE. Proceedings of the 23rd Australasian Software Engineering Conference. 2014, pp. 15-24.
[3] Annabelle Klarl, Lucia Cichella, and Rolf Hennicker. From Helena Ensemble Specifications to Executable Code. International Symposium on Formal Aspects of Component Software. Lecture Notes of Computer Science. to appear 2014.
Can component policies be exploited by external reasoners?
In a scenario like the e-mobility one, e-vehicles should be equipped with reasoning units capable of dealing with unexpected events, like e.g., failure in booking a parking lot, traffic jams, or unavailability of booked parking lots. To react to these situations, appropriate actions should be determined and taken. We discuss the reasoning issue in the context of SCEL, a formal language developed to program autonomic computing systems in terms of the constituent components and their reciprocal interactions.
As shown in Figure 1, a SCEL autonomic component results from the interaction among knowledge and behavior components, according to specific policies. These provide a simple, yet expressive, linguistic tool for defining and enforcing rules to specify strategies, requirements, constraints, guidelines, etc. about the behaviour of systems and of their components.
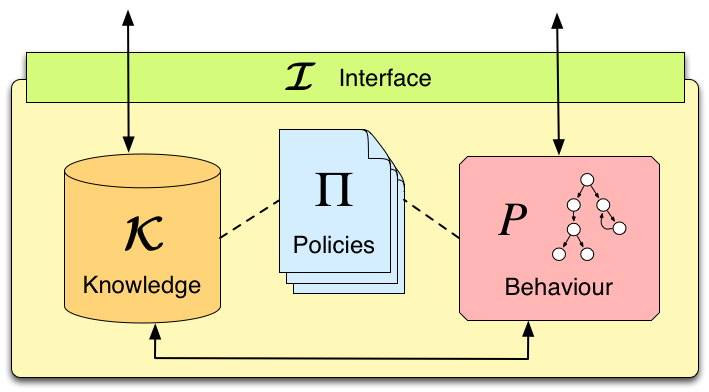
Figure 1: SCEL component
Policies may depend on the values of components' attributes (reflecting the status of components and their context) and can be dynamically modified for better reacting to system or environment changes. Moreover, as an effect of policy evaluation, specific actions, implementing adaptation strategies, can be produced at run-time and used to modify the behaviour of components.
Therefore, policies provide a simple form of self- and context-aware reasoning, supporting the achievement of self-* properties of the autonomic system. For example, when an e-vehicle is looking for available parking lots in nearby car parks, an internal policy could be used to ignore both parkings not equipped with charging station if the e-vehicle has a low battery level, and parkings with a cost per hour greater than a maximum cost established by the driver.
However, more sophisticated reasoning machineries can be necessary to deal with specific circumstances or when concerned with specific application domains. In these cases, separate reasoning units can be used by SCEL programs whenever decisions have to be taken.
Different reasoners, designed and optimised for specific purposes, can be exploited according to the components needs. Specifically, whenever SCEL systems have to take decisions, they have the possibility of invoking an external reasoner to receive informed suggestions about how to proceed. These answers would rely on the provided information about the relevant knowledge systems have access to and about their past behavior.
For example, in case of an unexpected event in the e-mobility scenario, a reasoner could be exploited by e-vehicles to dynamically re-plan their journey. Intuitively, the list of points-of-interest to be visited should be provided to the reasoner, which would shuffle it following some criteria, and would return the obtained list to the SCEL component that required it.
Figure 2 depicts such an enriched SCEL component, together with a generic external reasoner R. With respect to Figure 1, now local communications are filtered by a reasoner integrator RI (see post "Reasoning about reasoning agents").
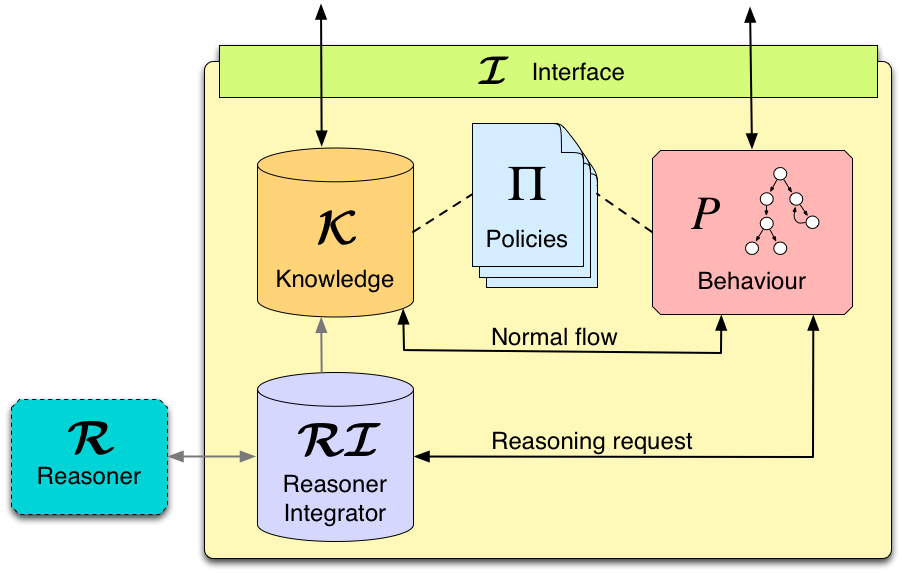
Figure 2: SCEL component with external reasoner
What we envisage is using policies not only for regulating components interaction, but also for managing the use of external reasoners. Policies could instruct the reasoners according to specific conditions on the internal status of the component and on external factors. For example, policies could urge the reasoner to return a solution as soon as possible, thus avoiding an exhaustive search. Moreover, policies could act as a filter for input data sent to the reasoner (e.g., sensible information about the driver could be removed from his profile before passing it to the reasoner), as well as for output data (e.g., actions returned by the reasoner could be blocked if they violate the e-vehicle polices). Anyway, as shown in Figure 3, how to reconcile policing and external reasoning is still an open issue.
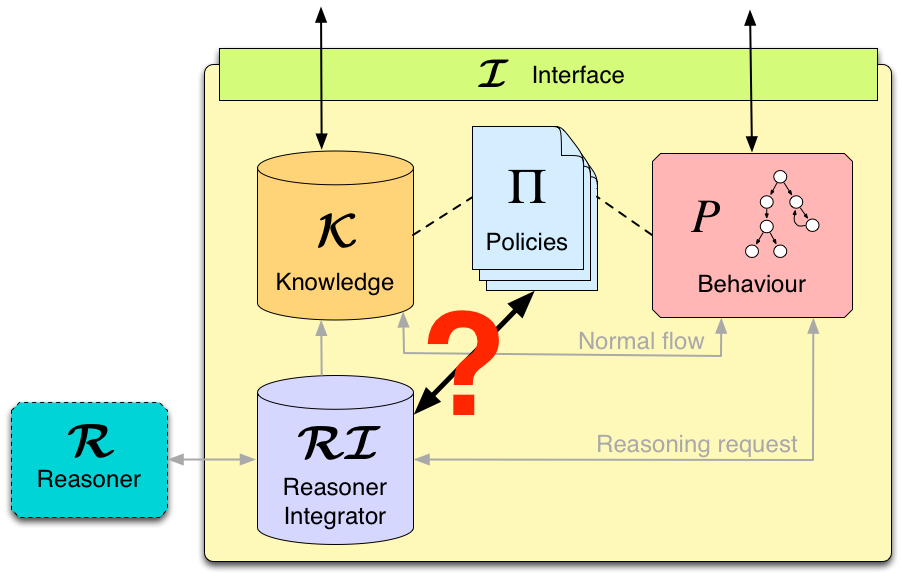
Figure 3: integration between policies and external reasoner
To tackle this issue, we should first be able to conceive under which conditions policies can help the reasoners, and to define appropriate interactions protocols between reasoners and policies handlers.
Rocco De Nicola and Francesco Tiezzi
IMT, Lucca
Reasoning about reasoning agents
Ensembles are systems consisting of a massive number of components that have the ability to dynamically adapt to environments that may change heavily during runtime. They pose a number of challenges. On the one hand, parallel activities of many heterogeneous components calls for knowledge sharing and coordination. On the other hand, dealing with changing environments and nondeterministic behaviors requires enabling ensemble components to reason about actions to take and their impact.
Auto-scooter, or “how to avoid bumpings”
Consider a grid world with an arbitrary number of agents moving in it. At every time step, agents can move up, down, left, right or decide to stand still. We concentrate on a single, partially informed agent that wonders in the area paying attention to minimizing its collisions with other, randomly moving, agents. Our agent perceives local information about the environment, but up to a limited perception range and has to exploit the available information to minimize collision risk.
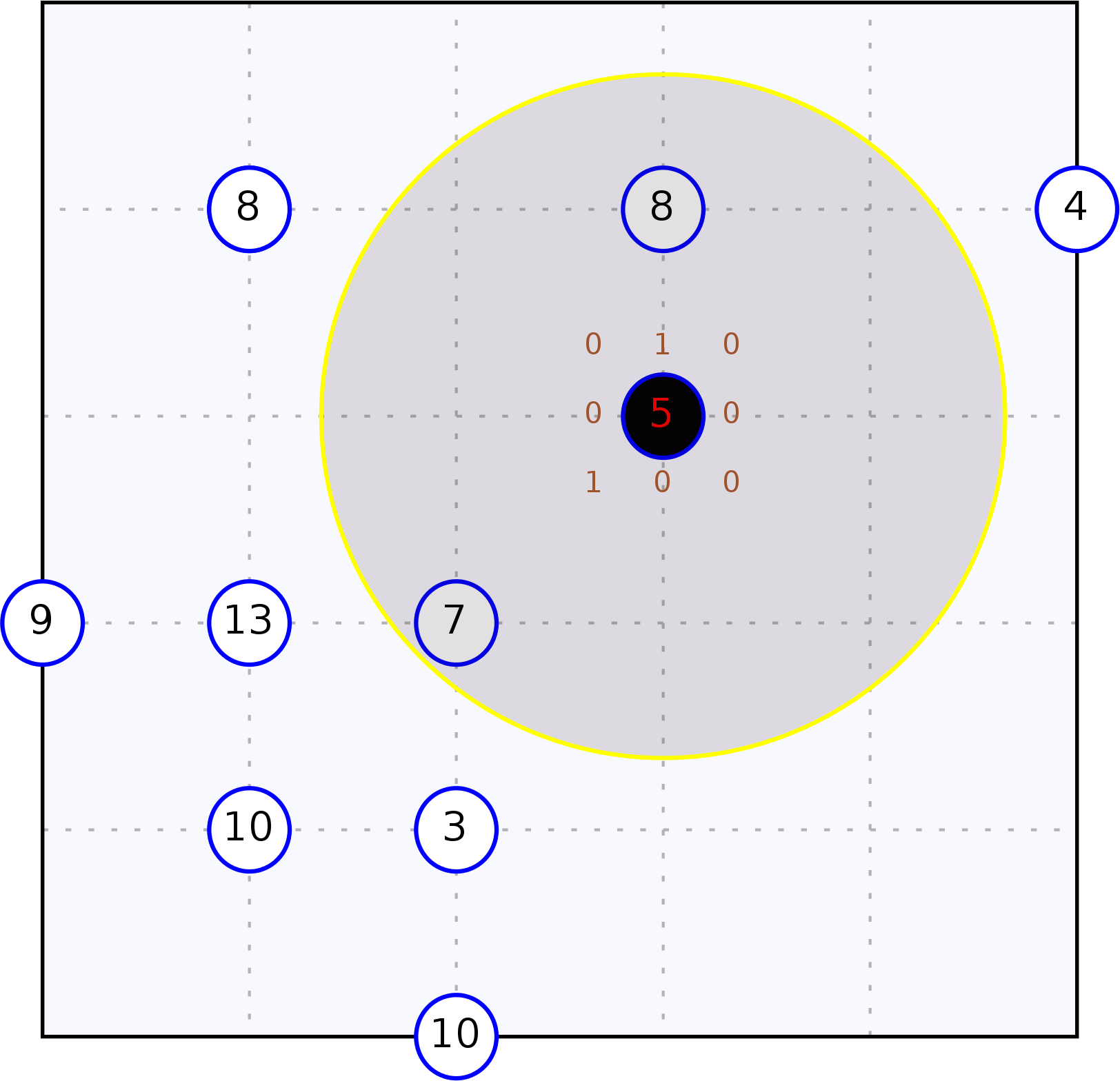
The figure depicts the scenario from a bird-eye perspective. The informed agent is the black circle surrounded by a wider semi-transparent circle representing its perception range. Blue circles represent randomly moving agents. Robots are labelled with their current number of collisions.
Modelling activities
In order to make an agent avoid others, as desired in the outlined scenario, it obviously has to move actively. The SCEL language [1] has been proposed to specify component behavior and to deal with the challenges that arise from the coordination of a massive number of components running in parallel. SCEL supports attribute-based communication and the management and sharing of information through tuple spaces that can for example serve as knowledge repositories. For the particular scenario, a SCEL implementation in the Maude language, MISSCEL, has been used to specify the informed agent's controller program. Maude provides a logical specification framework that allows to formally define the computational and deductional semantics of a language [2]; it also provides support for statistical model checking by the PVeStA tool [3].
Smart activities
In order to allow components to reason about actions to take, and thus to enable them to act autonomously and perform runtime adaptation, SCEL programs specifying components behavior can be connected to a reasoner. In the considered case study, the used reasoner is PiRLo [5], but the approach is viable for any reasoning system that can be triggered by a SCEL program via the tuple space. The fact that also PiRLo is written in the Maude language facilitates integration and allows for seamless usage with PVeStA. By using the formal approaches developed in the course of the ASCENS project, i.e., MISSCEL for modeling agents behaviors behavior and PiRLo for providing reasoning capabilities, it is possible to formally prove the quality of provided solutions. The PVeStA tool is used to generate measures that permit empirically comparing different solutions.
A headache: Formalisms integration
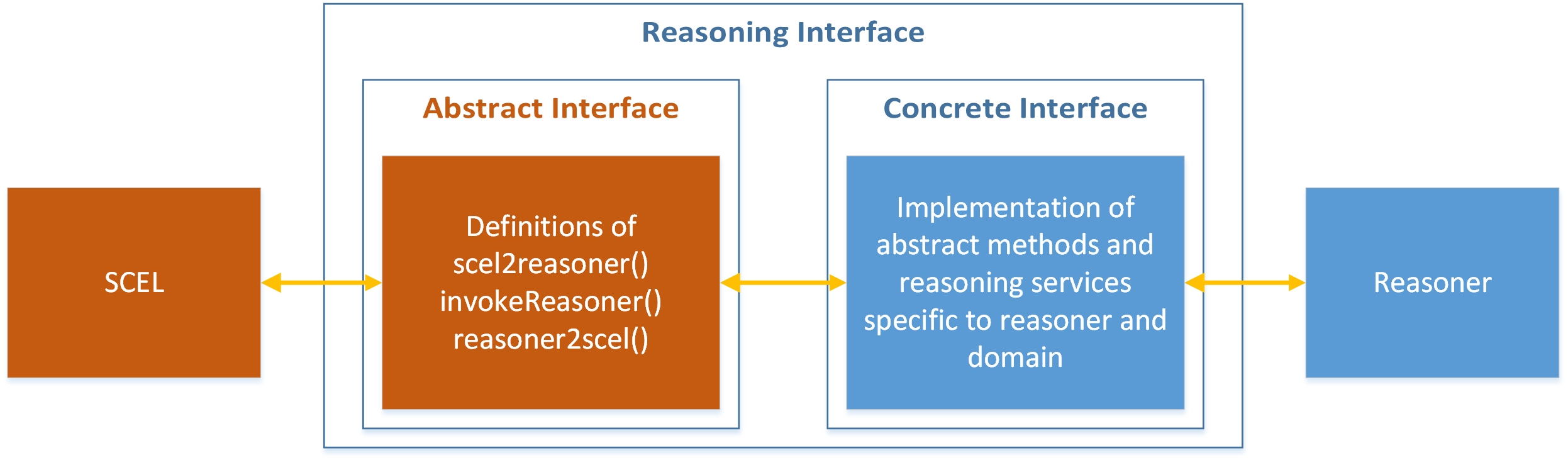
A common repository is used to integrate PiRLo with MISSCEL. There agents store their current perception and requests of specific services for the reasoner. When a SCEL program finds “reasoning tuples”, it invokes the reasoner via an abstract SCEL-reasoner interface. The wanted answer is obtained after three steps:
- Syntax and parameters of the reasoning request are translated from SCEL's representation to the reasoner's one.
- Reasoning is performed according to the requested reasoning service.
- Results provided by the reasoner are added to the tuple space of the requesting SCEL program.
Appropriate interfaces between the reasoner and SCEL guarantee a smooth interactions and hide implementation details of the adapter (consisting of both the abstract and the concrete interface). The figure below graphically outlines this approach.
At work!
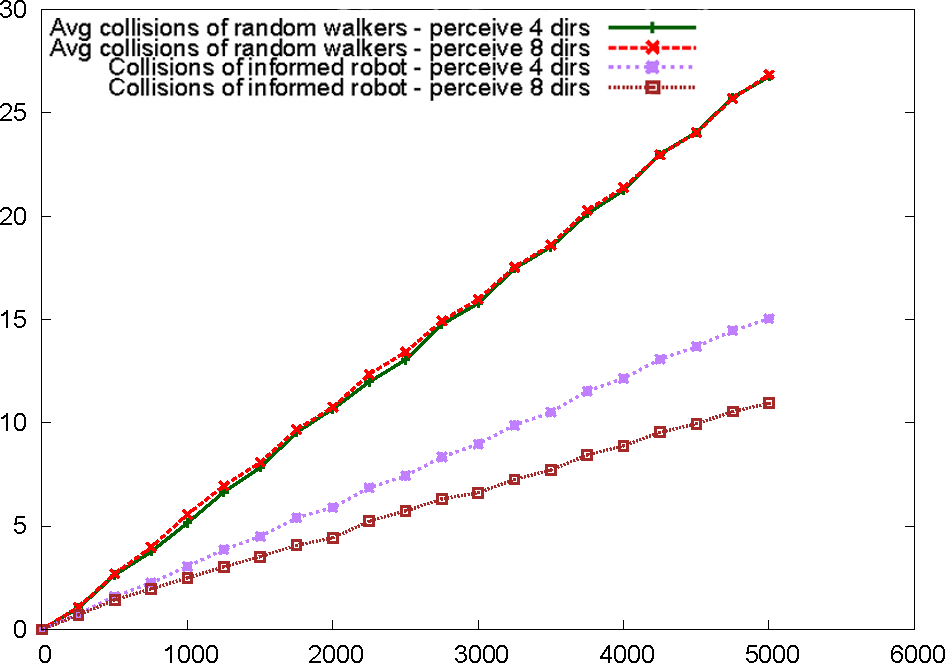
By providing a formal specification of the scenario in MISSCEL and PiRLo, it is possible to use a formal statistical model checking approach to empirically measure the quality of the proposed solutions. We implemented a SCEL program gathering information about the environment at every time step and triggering a reasoning service that provides the movement direction with the lowest probability of colliding with other agents. Upon receival of the wanted information, the informed agent moves as indicated by the reasoner. To evaluate the quality of the SCEL program, we measured the number of collisions detected in 5000 steps of simulation and compared the performance of our informed agent with that of an agent moving randomly. The figure below shows the results achieved by using the PVeStA statistical model checker. We considered two scenarios concerning an arena with 5*5 cells containing 10 normal robots and an informed one, all probabilistically distributed in the arena. In the first scenario the informed robot perceives only the four surrounding (4 dirs) positions while in the second it perceives also the positions along the diagonals (8 dirs). As one can would naturally expect, the integration of a reasoner improves the solution quality (i.e. reduces the numbers of collisions); through the presented approach of formal specification and statistical model checking, this intuitive result can also be proven empirically. The following image shows the results of the performed statistical analysis, while the video shows an exemplary simulation run.
The moral of the story
This blog presented an approach for rapid prototyping of service component ensembles that act autonomously in highly dynamic environments. To achieve this, component behavior has been specified in the MISSCEL implementation of the SCEL language and the PiRLo reasoner has been successfully integrated to MISSCEL via a well-defined interface to improve solution quality while maintaining separation of concerns. The presented approach for integration of reasoning via services is not limited to the particular implementations of SCEL or any reasoning component; it can be straightforwardly used for other implementations as well. As both the implementations of MISSCEL and PiRLo are realized in the Maude language, statistical model checking of provided solutions with the PVeStA model checker is straightforward. We provided evidence of the usefulness of the approach by comparing a solution exploiting the reasoner and one where agents only performs random movements.
A paper [5] detailing the results presented in this blog is under preparation.
In the future, we will look into hordes of reasoning agents (ensembles, yay!), e.g. by letting them explicitly talk to each other about their 'mental efforts'. Also, we could render the agents even smarter (yes, it is possible!), for example by providing them particular ontologies about the world they act in - already looking forward to some autoscooter-ontology.
If you'd like to know where we know all this from...
[1] De Nicola, R., Loreti, M., Pugliese, R., Tiezzi, F.: SCEL: a language for autonomic
computing. Tech. rep. (January 2013)
[2] Clavel, M., Duran, F., Eker, S., Lincoln, P., Marti-Oliet, N., Meseguer, J., Talcott,
C.L.: All About Maude, LNCS, vol. 4350. Springer (2007)
[3] AlTurki, M., Meseguer, J.: PVeStA: A parallel statistical model checking and
quantitative analysis tool. In: Corradini, A., Klin, B., Cîrstea, C. (eds.) CALCO
2011. LNCS, vol. 6859, pp. 386-392. Springer (2011)
[4] Belzner, L.: Action Programming in Rewriting Logic, to appear
[5] Rewriting Logic and Autonomic Computing: Modelling and Reasoning about Service Component Ensembles, by L. Belzner, R. De Nicola, A. Vandin and M. Wirsing, under preparation
QUANTICOL: A Quantitative Approach to Management and Design of Collective and Adaptive Behaviours
 QUANTICOL is a new research project funded by the FET-Proactive programme on Fundamentals of Collective Adaptive Systems. It aims to develop novel quantitative analysis techniques to support the design and operational management of a wide range of collective adaptive systems, with particular focus on applications arising in the context of smart cities. The concept of smart cities is on the research agenda of many EU and other international institutions and think-tanks. The following definition in a recent article on ‘Smart cities in Europe’, by Caragliu et al., gives insight in the prominent factors that are believed to generate smart cities: “We believe a city to be smart when investments in human and social capital and traditional (transport) and modern (ICT) communication infrastructure fuel sustainable economic growth and a high quality of life, with a wise management of natural resources, through participatory governance.” Although not the only factor for success of smart cities, innovative ICT-based technology is seen by many as a key factor that would allow modern cities to reach or maintain a good and sustainable quality of life for their inhabitants, with timely and equitable distribution of resources. At the core of many proposals ranging from smart buildings and transportation to a smart electricity grid, is the transformation of centralised system architecture and control to a much more decentralised and distributed design. Similar issues of optimal distribution and congestion avoidance play a role in smart transportation, whether based on public transport or community initiatives such as shared bikes. The very fact that such systems are highly distributed and their adaptive behaviour relies on the tight and continuous feedback between vast numbers of consumers and producers, makes such systems typical examples of large scale collective adaptive systems (CAS). These are systems that consist of a large number of spatially distributed heterogeneous entities with decentralised control and varying degrees of complex autonomous behaviour.
QUANTICOL is a new research project funded by the FET-Proactive programme on Fundamentals of Collective Adaptive Systems. It aims to develop novel quantitative analysis techniques to support the design and operational management of a wide range of collective adaptive systems, with particular focus on applications arising in the context of smart cities. The concept of smart cities is on the research agenda of many EU and other international institutions and think-tanks. The following definition in a recent article on ‘Smart cities in Europe’, by Caragliu et al., gives insight in the prominent factors that are believed to generate smart cities: “We believe a city to be smart when investments in human and social capital and traditional (transport) and modern (ICT) communication infrastructure fuel sustainable economic growth and a high quality of life, with a wise management of natural resources, through participatory governance.” Although not the only factor for success of smart cities, innovative ICT-based technology is seen by many as a key factor that would allow modern cities to reach or maintain a good and sustainable quality of life for their inhabitants, with timely and equitable distribution of resources. At the core of many proposals ranging from smart buildings and transportation to a smart electricity grid, is the transformation of centralised system architecture and control to a much more decentralised and distributed design. Similar issues of optimal distribution and congestion avoidance play a role in smart transportation, whether based on public transport or community initiatives such as shared bikes. The very fact that such systems are highly distributed and their adaptive behaviour relies on the tight and continuous feedback between vast numbers of consumers and producers, makes such systems typical examples of large scale collective adaptive systems (CAS). These are systems that consist of a large number of spatially distributed heterogeneous entities with decentralised control and varying degrees of complex autonomous behaviour.

Bike sharing in Paris (1)
A further characteristic of such systems is that often humans are both agents within such systems and end-users standing outside them. As end-users, they may be completely unaware of the sophisticated underlying technology needed to fulfil critical socio- technical goals such as effective transportation, communication, and work. The pervasive but transparent nature of CAS, together with the importance of the goals that they address, mean that it is imperative that thorough, a priori, analysis of their design is carried out to investigate all aspects of their behaviour, including quantitative and emergent aspects, before they are put into operation. We want to have high confidence that, once operational, they can adapt to changing requirements autonomously without operational disruption.
© Copyright: Donald Stirling, Polmont, Falkirk, Scotland
Literature about appropriate scalable development methods or frameworks is still scarce and there are very few design methodologies, common modelling languages or model-based formal verification approaches for either functional or non-functional properties. This holds in particular for the design of systems in which spatial homogeneity cannot be assumed to be a property of the system. Also integrated theoretical foundations are still lacking. The longer term research vision of the EU-FET Pro-active project QUANTICOL, that started on April 1st, 2013, is the development of a well- founded formal design and quantitative analysis framework for CAS and a comprehensive software engineering environment, supporting a model-based design methodology for the development of CAS for smart city applications taking non-functional properties into account. Such a design framework will also enable and facilitate experimentation and discovery of new design patterns for emergent behaviour and control over spatially distributed CAS. To reach this objective, the QUANTICOL project brings together two distinct research communities. These are Formal Methods (stochastic process algebras, (stochastic) logics and associated verification techniques); and Applied Mathematics (mean field/continuous approximation and control theory). The exploitation of mean-field approaches and the development of statistical simulation/model-checking techniques to analyse properties of stochastic process algebraic models are two very promising developments to overcome limitations in scalability and provide powerful novel verification tools for CAS.
This project will also build on the experience and results of the ASCENS project for what concerns the foundations and techniques to model and analyse Autonomic Service Components Ensembles.
Smart grid
The principal case studies that will drive the development of the new framework consider CAS of socio-technical nature. The first is based on scalability analysis and capacity planning for smart urban transportation systems. Such systems are being adopted in many European cities to reduce CO2 emissions and pollutants and encourage green means of transportation. The main issues are ensuring that there is sufficient capacity within the system to avoid traffic congestion and traffic diversion, and investigation of the effect on users of adaptive, spatially dependent incentives. The second case study considers smart grid applications. In particular, the development of a general modelling and analysis framework will be driven by a number of problems regarding the modelling, prediction and control of such smart grids.
The QUANTICOL project is part of the EU FP7 FET Proactive Initiative on Fundamentals of Collective Adaptive Systems (FOCAS). The QUANTICOL consortium is composed of five partners:
• The University of Edinburgh, Edinburgh, U.K.
• The National Research Council of Italy, ISTI, Pisa, Italy
• Ludwig-Maximilians Univerity (LMU) Muenchen, Munich, Germany
• Ecole Polytechnique Federale de Lausanne, Lausanne, Switzerland
• IMT Institute for Advanced Studies, Lucca, Italy
![]()
![]()
![]()
![]()
![]()
Further information on the project can be found at: http://www.quanticol.eu.
(1) Susan Shaheen and Stacey Guzman (Fall 2011), "Worldwide Bikesharing". Access Magazine No. 39. University of California Transportation Center. Retrieved 2013-05-14 via wikipedia.
A network-aware extension of the pi-calculus
A key aspect of modern network architectures is the possibility of manipulating the network structure at run-time. For instance, in Software Defined Networks [1] switches are instructed to install or remove forwarding rules at run-time by a controller machine; in IaaS Cloud Computing systems new nodes and links, equipped with a specific amount of storage, bandwidth, access rights..., can be allocated whenever needed.
Traditional process calculi, such as the pi-calculus, CCS and others, seem inadequate to describe these kinds of systems, because they abstract away from network details. In this post we give an overview of Network Conscious pi-calculus (NCPi) [1,2], an extension of the pi-calculus with a natural notion of network. Following [2], we will first present a core version of NCPi, closer to the pi-calculus: we will recall the basic primitives of the pi-calculus and compare them with those of NCPi. Finally, we will present the "full-fledged" calculus.
Base calculus
The pi-calculus models communication over channels. These are represented as pure names, that are entities characterized only by their identity. The novelty w.r.t. CCS is that communicated data are channels themselves, so processes can increase their communication capabilities during computation. The basic operations are output and input along channels: ab.p is a process that can send b along a and continue as p, and a(x).q can receive at a some datum that will replace x in the continuation q.
NCPi models communication over a network. There are two kinds of names: sites, atomic names of the form a representing network nodes, and links, structured names of the form lab, representing a link with name l from a to b. In addition to the same input and output primitives as the pi-calculus, NCPi also has a primitive to activate a link: lab.p is a process that can provide a transportation service over lab to the environment and continue as p.
Both calculi have operators for executing two processes p and q in parallel, written p | q, and in a non-deterministic fashion, written p + q. The parallel execution may give rise to synchronizations, when the involved processes exchange messages. The synchronization mechanism is one major difference between the pi-calculus and NCPi. Both scenarios are exemplified in the following figures, where each process is depicted as a square with tentacles to its free names (only the relevant names are shown, which we assume to occur also in the subprocesses).

Synchronization in the pi-calculus
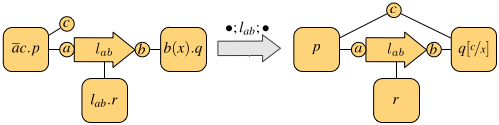
Synchronization in NCPi
The first figure shows the synchronization of the pi-calculus processes ab.p | a(x).q on the shared channel a: this gives rise to the observation tau and results in p and q sharing the channel b. In general, the pi-calculus only allows communication on shared channels, whereas NCPi is able to model remote communications. In fact, the second figure shows two processes that do not share output and input sites, but there is a process executing in parallel that provides a link between them, thus enabling the communication. The resulting observation is the link traversed by the datum. In general, a single communication may use a chain of links of arbitrary length.
NCP inherits the mechanism for creating and communicating new resources from the pi-calculus: fresh, unguessable sites and links are declared via the restriction operator (x)p, which binds x in p; communication of bound names enlarges their scope to the receiving process, which can use such names from then on. This is the mechanism that captures mobility.
Concurrent calculus
The calculus presented so far has an interleaving semantics, meaning that the behavior of parallel processes is given by their interleaved execution. This implicitly assumes the existence of a central arbiter who decides in which order resources should be accessed. However, such assumption can be considered inadequate for distributed systems with partially asynchronous behavior. We propose a version of NCPi which is closer to "real-life" networks. Its main features are:
- the output operator is of the form abc.p, modeling the emission of a packet from a with destination b and payload c.
- the semantics is concurrent, in the sense that many transmissions can be observed at the same time.
Concurrency in the semantics allows the associated behavioral equivalence to distinguish a parallel process from its interleaving counterpart (technically speaking, this avoids the usual counterexample where ab.a'(x) + a'(x).ab cannot simulate ab | a'(x) whenever a is identified with a', because the two processes are not equivalent in the first place). Indeed, it can be shown that such equivalence is preserved by all NCPi operators.
An example of parallel execution is depicted in the following figure.
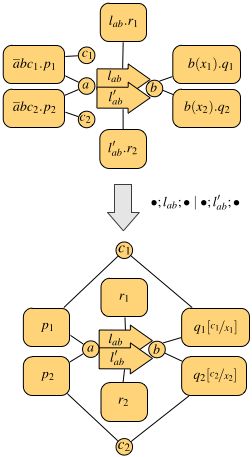
The top process has two links between a and b (for instance, one could be wired and the other one wireless). This enables the two processes on the left to transmit their data, both from a and addressed to b, at the same time. In fact, the resulting observation is made of two communications, each using one of the links from a to b, and both input variables are instantiated with actual values in the continuation (the bottom process).
[1] U. Montanari and M. Sammartino. Network conscious -calculus: A concurrent semantics. Electr. Notes Theor. Comput. Sci., 286:291–306, 2012. Available at http://www.di.unipi.it/ sammarti/papers/mfps28.pdf.
[2] U. Montanari and M. Sammartino. A network-conscious pi-calculus and its coalgebraic semantics. Theor. Comput. Sci. To Appear.
Analysing collective decision-making in swarm robotics
[Mieke Massink (ISTI) -- Joint work with Manuele Brambilla (ULB), Diego Latella (ISTI), Mauro Birattari (ULB) and Marco Dorigo (ULB)]
Analysing large and complex swarm robotics systems using physics-based simulations or directly with robots is often difficult and time consuming. For this reason, a common way to study these systems is by using abstract models. Models allow the developer to abstract from the complexity of a system and its implementation details and focus on the aspects that are relevant for the analysis.
An interesting problem in swarm robotics is how one can instruct robots in a swarm to make collective and optimal decisions. A further problem is then to find out whether a proposed strategy for decision making is indeed working as expected. The difficulties are caused by the fact that each robot in the swarm is on one hand operating independently from the others and on the other hand also cooperating with them and implicitly interacting with the environment creating feedback loops. Such feedback loops are known to be the cause of interesting phenomena such as that of emergent behaviour in the overall system that may sometimes be a desired effect as in the case of collective decision making.
Let's have a look at a concrete example and consider a swarm of robots that need to carry objects from a start area to a goal area. To carry an object, three robots are needed that work as a team. The start and the goal areas are connected by two paths: a short path and a twice as long path. The robots have to collectively identify and choose the shortest path. They do so by a voting process based on the majority rule [1] by the members of each team. Each robot has a preferred path. When a group is formed in the start area (Figure 1(a)), a vote takes place and the group chooses the path that is preferred by the majority of the robots it is composed of (Figure 1(b)). The chosen path also becomes the new preferred path for all the robots composing the group (Figure 1(e)). For example, if two robots prefer the short path and one robot prefers the long path, the short path is chosen for the next run and the robot that preferred the long path changes its preference to the short path. Note that the voting process takes place only in the start area and no other event can change the preference of the robots. Figure 1 shows a schema of the scenario. Initially half of the swarm prefers the short path and the other half the long one.
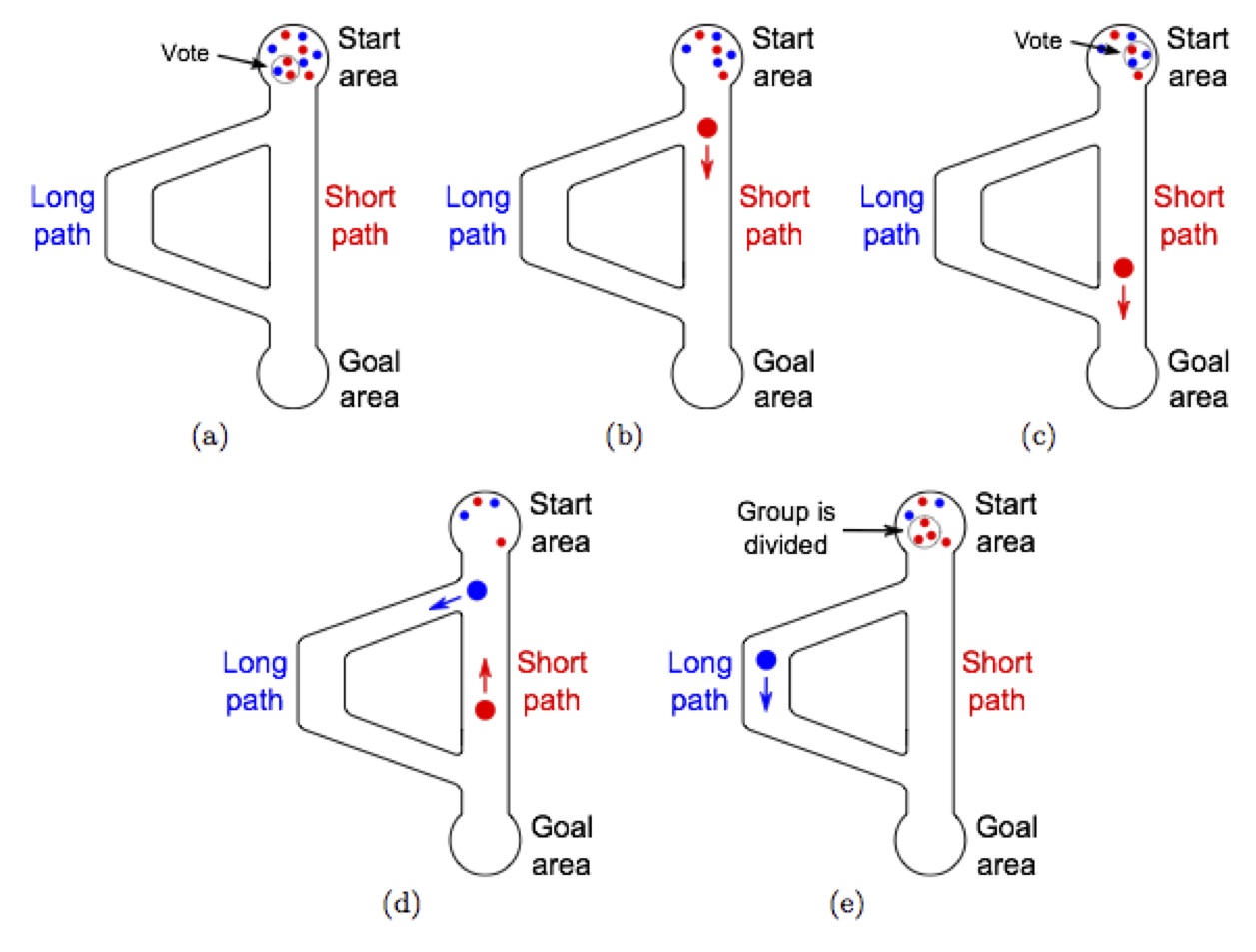
Fig. 1: Scenario
Since the robots taking the short path spend less time out of the start area than the robots taking the long path, their participation in the vote is, on average, more frequently establishing a positive feedback on the preference to vote for the short path. This results over time in the formation of more teams preferring the short path.
Recently, high-level modelling languages have been developed with which collective behaviour can be modelled using a population-oriented view-point. One of these languages is Bio-PEPA developed by Hillston et al. It is a variant of stochastic process algebra and therefore has important and useful properties such as compositionality: the overall system can be built from smaller basic components. But at least as important, different mathematical models can be derived from a Bio-PEPA specification that can be used in particular to analyse systems with a very large number of components applying analysis techniques such as stochastic simulation, statistical model checking and fluid flow analysis (see Fig. 2). The latter is a method that approximates, in a deterministic way, via differential equations, the change over time of the number of objects that are in a particular state. In our case for example the number of robots that prefer the short path.
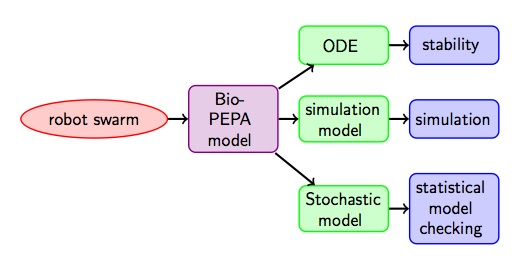
Fig. 2: Bio-PEPA analysis
This combination of a high-level language and sophisticated scalable analysis techniques makes it possible to analyse also swarms of large dimensions in an efficient way.
The idea of statistical model checking is to generate random executions of the system model and check whether they satisfy a particular property of interest (see Fig. 3). Statistical methods are then applied on the outcomes of those checks.
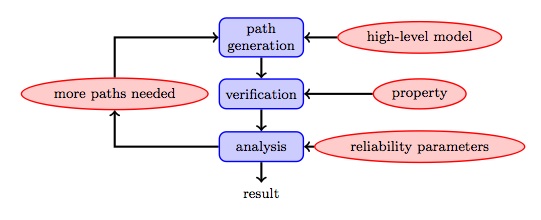
Fig. 3: Statistical Model-checking
For example, we can then automatically check what is the probability that the swarm reaches a decision and, if so, what is the probability that it is the desired decision. In Fig. 4 below the probability of convergence on the shortest path is shown for different average numbers of active teams k (and thus different numbers of robots that are in the start area at any time). For a swarm of 32 robots and with one path twice as long as the other the best probability is reached when there are on average about eight teams active. The results obtained with statistical model checking are comparable with those obtained via more common swarm robotics analysis methods such as physics-based simulation, but require much less time to be performed.
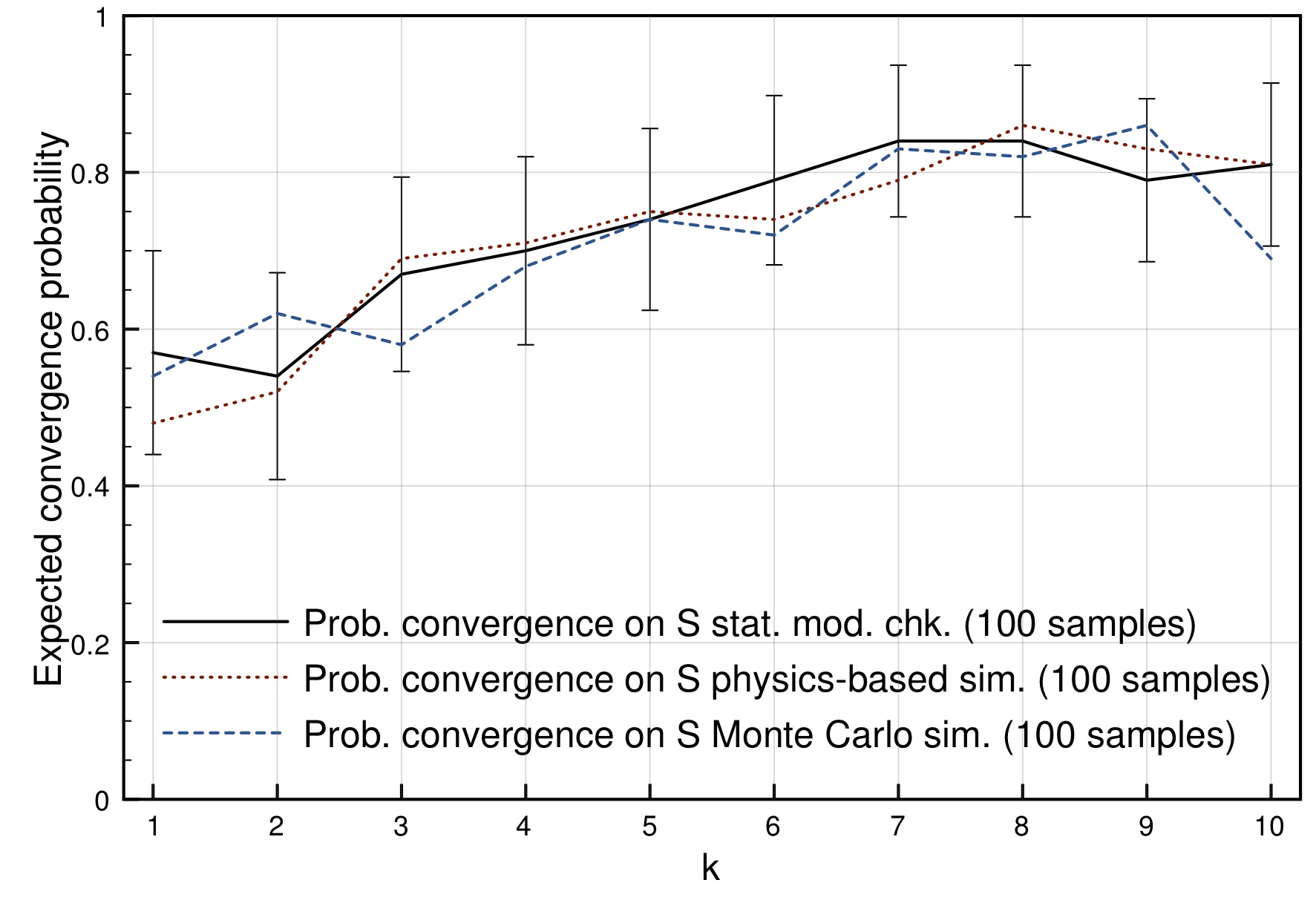
Fig. 4: Probability of convergence
What is even more of interest is that starting from a high-level language as Bio-PEPA it is easy to check what happens with the system under different circumstances. For example, what would happen if in the beginning the preferences for the different paths were not equally distributed among the robots in the start area. Or what would happen if most of the time almost all robots are away from the start area and the composition of teams could get easily biased or vary a lot due to the small number of robots from which a team would be selected. Or what would happen if some percentage of the robots would refuse to adjust their preference to comply with the majority.

Fig. 5: ODE solution
Fluid flow analysis of the same model may provide a computationally efficient way to get insight in the average behaviour of the swarm for very large populations. In Fig. 5 we see results for a swarm composed of 32,000 robots, all initially in the start area and then, when time passes many robots in the swarm leave this area and after a short while robots in favour of the short path S are increasingly dominating the population. The figure shows that the results of stochastic simulation (G1) of the whole system and the fluid (ODE) analysis are showing good correspondence, but the latter results are much faster to obtain and are insensitive to the actual size of the population.
A further research challenge will focus on analysing the effectiveness of decision strategies that can dynamically adapt to changing circumstances such as new shorter paths being created or optimal paths getting inaccessible.
References for further reading:
[1] M. A. Montes de Oca, E. Ferrante, A. Scheidler, C. Pinciroli, M. Birattari, and M. Dorigo. Majority-rule opinion dynamics with differential latency:
A mechanism for self-organized collective decision-making. Swarm Intelligence, 5(3-4):305-327, 2011.
[2] M. Massink, M. Brambilla, D. Latella, M. Dorigo, and M. Birattari. Analysing
robot swarm decision-making with Bio-PEPA. In Swarm Intelligence,
volume 7461 of Lecture Notes in Computer Science, pages 25-36. Springer,
Heidelberg, 2012.
[3] M. Massink, M. Brambilla, D. Latella, M. Dorigo, and M. Birattari. On the use of Bio-PEPA for Modelling and Analysing Collective Behaviours in Swarm Robotics. Swarm Intelligence, April 2013.
The Need of Rigorous Design of Ensembles
The increasing immersion and interaction of computing systems in both physical systems and societal systems, inevitably poses the problem of the nature of computing and its relationship to other scientific disciplines. What is the very nature of computing? How the interplay between different types of systems (physical, computing, biological) can be understood and mastered? To what extent can multi-disciplinary system-centric approaches contribute to a cross-fertilization of other disciplines?
Computing is a scientific discipline in its own right with its own concepts and paradigms. It deals with problems related to the representation, transformation and transmission of information. Information is an entity distinct from matter and energy. It is a resource that can be stored, transformed, transmitted and consumed. It is immaterial but needs media for its representation by using languages characterized by their syntax and semantics
Computing is not merely a branch of mathematics. Just as any other scientific discipline, it seeks validation of its theories on mathematical grounds. But mainly, and most importantly, it develops specific theory intended to explain and predict properties of systems that can be tested experimentally.
The advent of embedded systems brings computing closer to physics. Linking physical systems and computing systems requires a better understanding of differences and points of contact between them. Is it possible to define models of computation encompassing quantities such as physical time, physical memory and energy? Significant differences exist in the approaches and paradigms adopted by the two disciplines.
Physics is based on continuous mathematics while computing is rooted in discrete non-invertible mathematics. Physics studies a given “reality” and tries to discover laws governing physical phenomena while computing systems are human artifacts. Its laws are declarative by their nature. Physical systems are specified by differential equations involving relations between physical quantities. The essence of many physical phenomena can be captured by simple linear laws. They are, to a large extent, deterministic and predictable. Synthesis is the dominant paradigm in physical systems engineering. We know how to build artifacts meeting given requirements (e.g. bridges or circuits), by solving equations describing their behavior. By contrast, state equations of very simple computing systems, such as an RS flip-flop, do not admit linear representations in any finite field. Computing systems are described in executable formalisms such as programs and machines. Their behavior is intrinsically non-deterministic. Non-decidability of their essential properties implies poor predictability.
Computing enriches our knowledge with theory and models enabling a deeper understanding of discrete dynamic systems. It proposes a constructive and operational view of the world which complements the classic declarative approach adopted by physics.
Living organisms intimately combine interacting physical and computational phenomena that have a deep impact on their development and evolution. They share several characteristics with computing systems such as the use of memory, the distinction between hardware and software, and the use of languages. However, some essential differences exist. Computation in living organisms is robust, has built-in mechanisms for adaptivity and, most importantly, it allows the emergence of abstractions and concepts. We believe that these differences delimit a gap that is hard to be filled by actual computing systems.
The Design of Trustworthy Ensembles
The need for rigorous design is sometimes directly or indirectly questioned by developers of large-scale ensembles. These are systems of overwhelming complexity. They consist of an immense number of interconnected components and are built incrementally in an ad hoc manner. Their behavior can be studied only empirically by testing and through controlled experiments. The key issue is to determine tradeoffs between performance and cost by iterative tuning of parameters. Currently, a good deal of research on cloud-based or web-based systems privileges an analytic approach that aims to find laws that generate or explain observed phenomena rather than to investigate design principles for achieving a desired behavior. It is reported in [1] that “On line companies […] don’t anguish over how to design their Web sites. Instead they conduct controlled experiments by showing different versions to different groups of users until they have iterated to an optimal solution”.
This trend calls for two remarks.
- In contrast to physical sciences, computing is predominantly synthetic. Its main goal is to develop theory, methods and tools for building trustworthy and optimized computing systems. Considering the cyber-universe as a “given reality” driven by its own laws and privileging analytic approaches for their discovery and study, is epistemologically absurd and can have only limited scientific impact. The physical world is the result of a long and well-orchestrated evolution. It is governed by simple laws. To quote Einstein, “the most incomprehensible thing about the world is that it is at all comprehensible”. The trajectory of a projectile under gravity is a parabola which is a very simple and easy to understand law. There is nothing similar about programs or computing systems.
- Ad hoc and experimental approaches can be useful only for optimization purposes. Trustworthiness is a qualitative property and by its nature cannot be achieved by the fine tuning of parameters. Small changes can have a dramatic impact on safety and security properties.
We need theoretical frameworks that are expressive, make use of a minimal set of high level concepts and primitives for system description and that are amenable to formalization and analysis. Is it possible to find a mathematically elegant and still practicable theoretical framework for ensembles? We cannot expect to have theoretical settings as beautiful and as powerful as those for physical systems. One more profound reason is that computing systems are human artifacts while the physical systems are the result of a very long evolution.
In contrast to physical sciences that focus mainly on the discovery of laws, computing should focus mainly on theory for correct-by-construction and predictable system design. Design is central to the discipline. Awareness of its centrality is a chance to reinvigorate research, and build new scientific foundations matching the needs for increasing system integration and new applications.
There already exists a large body of correct-by-construction results such as algorithms, architectures and protocols. Their application allows correctness for (almost) free. How can global properties of ensembles be effectively inferred from the properties of their constituents? This remains an old open problem that urgently needs answers. Failure to bring satisfactory solutions will be a limiting factor for ensemble integration. It would also mean that computing is definitely relegated to second-class status with respect to other scientific disciplines.
J. Sifakis.
[1] Timo Hannay “The Controlled Experiment” in John Brockman “This will make you smarter”, Happer Perennial.
Engineering Distributed Adaptive Systems using Components
Traditional software engineering methodologies together with related programming paradigms have long been guiding the procedure of building software systems through the requirements and design phase to testing and deployment. In particular, engineering paradigms based on the notion of components have gained a lot of popularity as they support separation of concerns - extremely valuable when dealing with systems of high complexity.
It seems, though, that these traditional methodologies and paradigms are not sufficient when exploited in the domain of continuously changing, massively distributed and dynamic systems, such as the ones we explore in the ASCENS project. These systems need to adjust to changes in their architecture and environment seamlessly or, even better, acknowledge the absence of absolute certainty over their (constantly changing) architecture and environment. An appealing research direction seems to be the decomposition of such systems into components able to operate upon temporary and volatile information in an autonomous and self-adaptive fashion. From the software engineering perspective, two main challenges arise:
- What are the correct low-level abstractions (models, respective paradigms) that will allow for separation of concerns?
- How can we devise a systematic approach for designing such systems, exploiting the above abstractions?
In response, we propose the DEECo component model (stands for Dependable Emergent Ensembles of Components). The goal of the component model is allow for designing systems consisting of autonomous, self-aware, and adaptable components, which are implicitly organized in groups called ensembles. To this end, we propose a slightly different way of perceiving a component; i.e., as a self-aware unit of computation, relying solely on its local data that are subject to modification during the execution time. The whole communication process relies on automatic data exchange among components, entirely externalized and automated within the runtime. This way, the components have to be programmed as autonomous units, without relying on whether/how the distributed communication is performed, which makes them very robust and suitable for rapidly-changing environments.
Main Concepts
DEECo is centered around two first-class concepts: component and ensemble. These two concepts closely reflect fundamentals of the SCEL specification language. In fact, DEECo is meant to be a component model that provides software engineering constructs for SCEL concepts. Consequently, the behavior of a system of DEECo components and ensembles can be described in SCEL in a straightforward way. The two first-class DEECo concepts are in detail elaborated below:
Component
A component is an autonomous unit of deployment and computation. Similar to SCEL, it consists of:
- Knowledge
- Processes
Knowledge contains all the data and functions of the component. It is a hierarchical data structure mapping identifiers to (potentially structured) values. Values are either statically typed data or functions. Thus DEECo employs statically-typed data and functions as first-class entities. We assume pure functions without side effects.
Processes, each of them being essentially a “thread”, operate upon the knowledge of the component. A process employs a function from the knowledge of the component to perform its task. As any function is assumed to have no side effects, a process defines mapping of the knowledge to the actual parameters of the employed function (input knowledge), as well as mapping of the return value back to the knowledge (output knowledge). A process can be either periodic or triggered. A process can be triggered when its input knowledge changes or when a given condition on the component’s knowledge (guard) is satisfied.
Ensemble
Ensembles determine composition of components. Composition is flat, expressed implicitly via a dynamic involvement in an ensemble. An ensemble consists of multiple member components and a single coordinator component. The only allowed form of communication among components is communication between a member and the coordinator in an ensemble. This allows the coordinator to apply various communication policies.
Thus, an ensemble is described pair-wise, defining the couples coordinator – member. An ensemble definition consists of:
- Required interface of the coordinator and a member
- Membership function
- Mapping function
Interface is a structural prescription for a view on a part of the component’s knowledge. An interface is associated with a component’s knowledge by means of duck typing; i.e., if a component’s knowledge has the structure prescribed by an interface, then the component reifies the interface. In other words, an interface represents a partial view on the knowledge.
Membership function declaratively expresses the condition, under which two components represent the pair coordinator-member of an ensemble. The condition is defined upon the knowledge of the components. In the situation where a component satisfies the membership functions of multiple ensembles, we envision a mechanism for deciding whether all or only a subset of the candidate ensembles should be applied. Currently, we employ a simple mechanism of a partial order over the ensembles for this purpose (the “maximal” ensemble of the comparable ones is selected, the ensembles which are incomparable are applied simultaneously).
Mapping function expresses the implicit distributed communication between the coordinator and a member. It ensures that the relevant knowledge changes in one component get propagated to the other component. However, it is up to the framework when/how often the mapping function is invoked. Note that (except for component processes) the single-writer rule applies also to mapping function. We assume a separate mapping for each of the directions coordinator-member, member-coordinator.
The important idea is that the components do not know anything about ensembles (including their membership in an ensemble). They only work with their own local knowledge, which gets implicitly updated whenever the component is part of a suitable ensemble.
Example
To illustrate the above-described concepts, we’ll give an example from the Science Cloud case-study. In this scenario, several interconnected, heterogeneous network nodes (execution nodes, storage nodes) run a cloud platform, on which 3rd-party services are being executed. Moreover, the nodes can dynamically enter/leave the network. Provided an external mechanism for migrating a service from one (execution) node to another, the goal is to “cooperatively distribute the load of the overloaded (execution) nodes in the network.”
Solution in a Nutshell
Before describing the solution in DEECo concepts, we will give an outline of the final result. Basically, for the purpose of this illustration, we consider a simple solution, where each of the nodes tracks its own load and if the load is higher than a fixed threshold, it selects a set of services to be migrated out. Consequently, all the nodes with low-enough load (determined by another fixed threshold) are given information about the services selected for migration, pick some of them and migrate them in using the external migration mechanism.
The challenge here is to decide which of the nodes the service information should be given to and when, since the nodes join and leave the network dynamically. In DEECo, this is solved by describing such a node interaction declaratively, so that it can be carried out in an automated way by the runtime framework when appropriate.
Realization in DEECo
Specifically, we first identify the components in the system and their internal knowledge. In this example, the components will be all the different nodes (execution/storage nodes) running the cloud platform (Figure 1). The inherent knowledge of execution nodes is their current load, information about running services, etc. We expect an execution node component to have a process, which determines the services to be migrated in case of overload. Similarly, the inherent knowledge of the storage nodes is their current capacity, filesystem, etc.
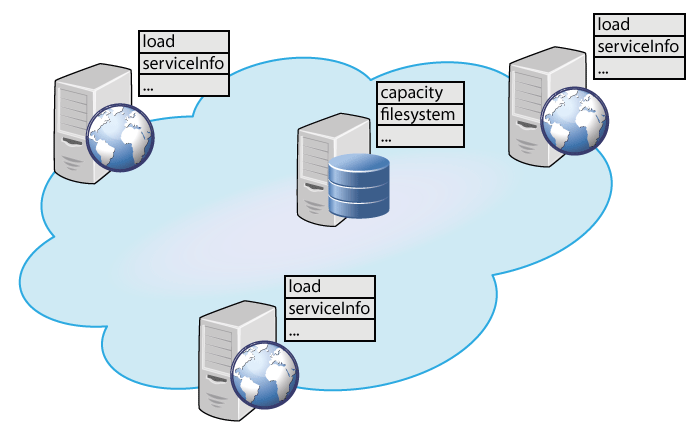
Figure 1. Components representing the cloud nodes and their inherent knowledge.
The second step is to define the actual component interaction and exchange of their knowledge. In this example, only the transfer of the information about services to be migrated from the overloaded nodes to the idle nodes is defined. The interaction is captured in a form of an ensemble definition (Figure 2), thus representing a “template” for interaction. Here, the coordinator, as well as the members, has to be an execution node providing the load and serviceInfo knowledge entries. Having such nodes, whenever the (potential) coordinator has the load above 90% and a (potential) member has the load below 20% (i.e., the membership function returns true), the ensemble is established and its mapping function is executed (possibly in a periodic manner). The mapping function in this case ensures exchanging the information about the services to be migrated from the coordinator to the members of the ensemble.
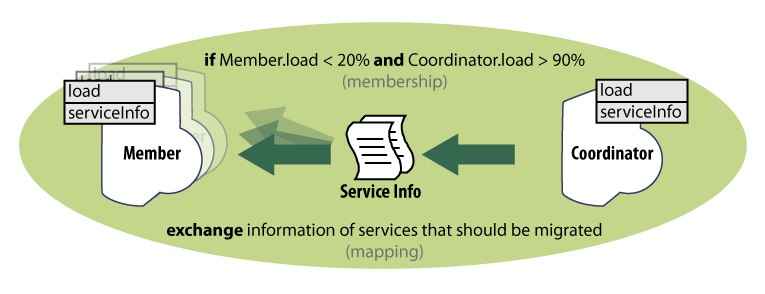
Figure 2. Definition of an ensemble that ensures exchange of the services to be migrated.
When applied to the current state of the components in the system, an ensemble - established according to the above-described definition - ensures an exchange of the service-to-be-migrated information among exactly the pairs of components meeting the membership condition of the ensemble (Figure 3).
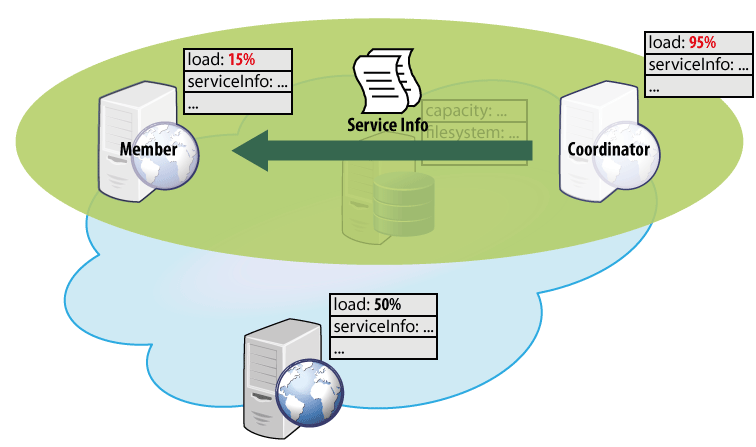
Figure 3. Application of the ensemble definition from Figure 2 to the components from Figure 1.
According to the exchange of service information, the member nodes then individually perform service migration via the external (i.e., outside of DEECo) migration mechanism.
Current Implementation & Future Vision
As for implementation, we work on a prototype based on distributed tuple spaces and implemented in Java. The sources, as well as documentation and examples, can be found at https://github.com/d3scomp/JDEECo.
We envision that the component model outlined here will serve as the basis for a design methodology that will exploit the presented abstractions and help in building long-lasting systems of service-components and service-component ensembles.