Engineering Distributed Adaptive Systems using Components
Traditional software engineering methodologies together with related programming paradigms have long been guiding the procedure of building software systems through the requirements and design phase to testing and deployment. In particular, engineering paradigms based on the notion of components have gained a lot of popularity as they support separation of concerns - extremely valuable when dealing with systems of high complexity.
It seems, though, that these traditional methodologies and paradigms are not sufficient when exploited in the domain of continuously changing, massively distributed and dynamic systems, such as the ones we explore in the ASCENS project. These systems need to adjust to changes in their architecture and environment seamlessly or, even better, acknowledge the absence of absolute certainty over their (constantly changing) architecture and environment. An appealing research direction seems to be the decomposition of such systems into components able to operate upon temporary and volatile information in an autonomous and self-adaptive fashion. From the software engineering perspective, two main challenges arise:
- What are the correct low-level abstractions (models, respective paradigms) that will allow for separation of concerns?
- How can we devise a systematic approach for designing such systems, exploiting the above abstractions?
In response, we propose the DEECo component model (stands for Dependable Emergent Ensembles of Components). The goal of the component model is allow for designing systems consisting of autonomous, self-aware, and adaptable components, which are implicitly organized in groups called ensembles. To this end, we propose a slightly different way of perceiving a component; i.e., as a self-aware unit of computation, relying solely on its local data that are subject to modification during the execution time. The whole communication process relies on automatic data exchange among components, entirely externalized and automated within the runtime. This way, the components have to be programmed as autonomous units, without relying on whether/how the distributed communication is performed, which makes them very robust and suitable for rapidly-changing environments.
Main Concepts
DEECo is centered around two first-class concepts: component and ensemble. These two concepts closely reflect fundamentals of the SCEL specification language. In fact, DEECo is meant to be a component model that provides software engineering constructs for SCEL concepts. Consequently, the behavior of a system of DEECo components and ensembles can be described in SCEL in a straightforward way. The two first-class DEECo concepts are in detail elaborated below:
Component
A component is an autonomous unit of deployment and computation. Similar to SCEL, it consists of:
- Knowledge
- Processes
Knowledge contains all the data and functions of the component. It is a hierarchical data structure mapping identifiers to (potentially structured) values. Values are either statically typed data or functions. Thus DEECo employs statically-typed data and functions as first-class entities. We assume pure functions without side effects.
Processes, each of them being essentially a “thread”, operate upon the knowledge of the component. A process employs a function from the knowledge of the component to perform its task. As any function is assumed to have no side effects, a process defines mapping of the knowledge to the actual parameters of the employed function (input knowledge), as well as mapping of the return value back to the knowledge (output knowledge). A process can be either periodic or triggered. A process can be triggered when its input knowledge changes or when a given condition on the component’s knowledge (guard) is satisfied.
Ensemble
Ensembles determine composition of components. Composition is flat, expressed implicitly via a dynamic involvement in an ensemble. An ensemble consists of multiple member components and a single coordinator component. The only allowed form of communication among components is communication between a member and the coordinator in an ensemble. This allows the coordinator to apply various communication policies.
Thus, an ensemble is described pair-wise, defining the couples coordinator – member. An ensemble definition consists of:
- Required interface of the coordinator and a member
- Membership function
- Mapping function
Interface is a structural prescription for a view on a part of the component’s knowledge. An interface is associated with a component’s knowledge by means of duck typing; i.e., if a component’s knowledge has the structure prescribed by an interface, then the component reifies the interface. In other words, an interface represents a partial view on the knowledge.
Membership function declaratively expresses the condition, under which two components represent the pair coordinator-member of an ensemble. The condition is defined upon the knowledge of the components. In the situation where a component satisfies the membership functions of multiple ensembles, we envision a mechanism for deciding whether all or only a subset of the candidate ensembles should be applied. Currently, we employ a simple mechanism of a partial order over the ensembles for this purpose (the “maximal” ensemble of the comparable ones is selected, the ensembles which are incomparable are applied simultaneously).
Mapping function expresses the implicit distributed communication between the coordinator and a member. It ensures that the relevant knowledge changes in one component get propagated to the other component. However, it is up to the framework when/how often the mapping function is invoked. Note that (except for component processes) the single-writer rule applies also to mapping function. We assume a separate mapping for each of the directions coordinator-member, member-coordinator.
The important idea is that the components do not know anything about ensembles (including their membership in an ensemble). They only work with their own local knowledge, which gets implicitly updated whenever the component is part of a suitable ensemble.
Example
To illustrate the above-described concepts, we’ll give an example from the Science Cloud case-study. In this scenario, several interconnected, heterogeneous network nodes (execution nodes, storage nodes) run a cloud platform, on which 3rd-party services are being executed. Moreover, the nodes can dynamically enter/leave the network. Provided an external mechanism for migrating a service from one (execution) node to another, the goal is to “cooperatively distribute the load of the overloaded (execution) nodes in the network.”
Solution in a Nutshell
Before describing the solution in DEECo concepts, we will give an outline of the final result. Basically, for the purpose of this illustration, we consider a simple solution, where each of the nodes tracks its own load and if the load is higher than a fixed threshold, it selects a set of services to be migrated out. Consequently, all the nodes with low-enough load (determined by another fixed threshold) are given information about the services selected for migration, pick some of them and migrate them in using the external migration mechanism.
The challenge here is to decide which of the nodes the service information should be given to and when, since the nodes join and leave the network dynamically. In DEECo, this is solved by describing such a node interaction declaratively, so that it can be carried out in an automated way by the runtime framework when appropriate.
Realization in DEECo
Specifically, we first identify the components in the system and their internal knowledge. In this example, the components will be all the different nodes (execution/storage nodes) running the cloud platform (Figure 1). The inherent knowledge of execution nodes is their current load, information about running services, etc. We expect an execution node component to have a process, which determines the services to be migrated in case of overload. Similarly, the inherent knowledge of the storage nodes is their current capacity, filesystem, etc.
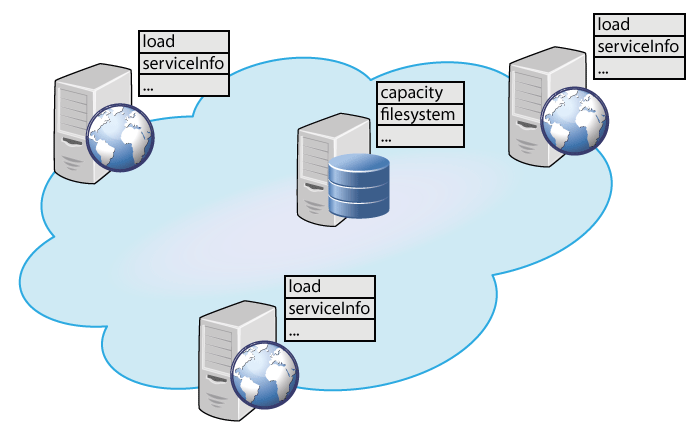
Figure 1. Components representing the cloud nodes and their inherent knowledge.
The second step is to define the actual component interaction and exchange of their knowledge. In this example, only the transfer of the information about services to be migrated from the overloaded nodes to the idle nodes is defined. The interaction is captured in a form of an ensemble definition (Figure 2), thus representing a “template” for interaction. Here, the coordinator, as well as the members, has to be an execution node providing the load and serviceInfo knowledge entries. Having such nodes, whenever the (potential) coordinator has the load above 90% and a (potential) member has the load below 20% (i.e., the membership function returns true), the ensemble is established and its mapping function is executed (possibly in a periodic manner). The mapping function in this case ensures exchanging the information about the services to be migrated from the coordinator to the members of the ensemble.
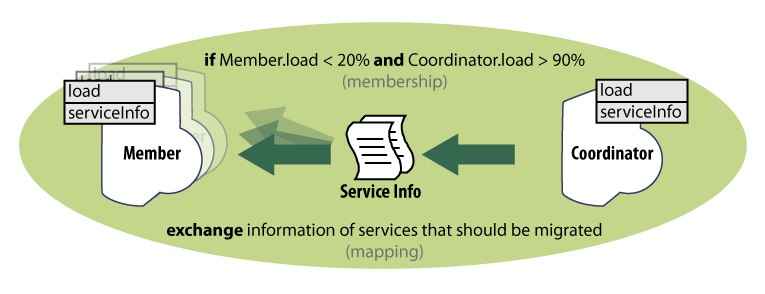
Figure 2. Definition of an ensemble that ensures exchange of the services to be migrated.
When applied to the current state of the components in the system, an ensemble - established according to the above-described definition - ensures an exchange of the service-to-be-migrated information among exactly the pairs of components meeting the membership condition of the ensemble (Figure 3).
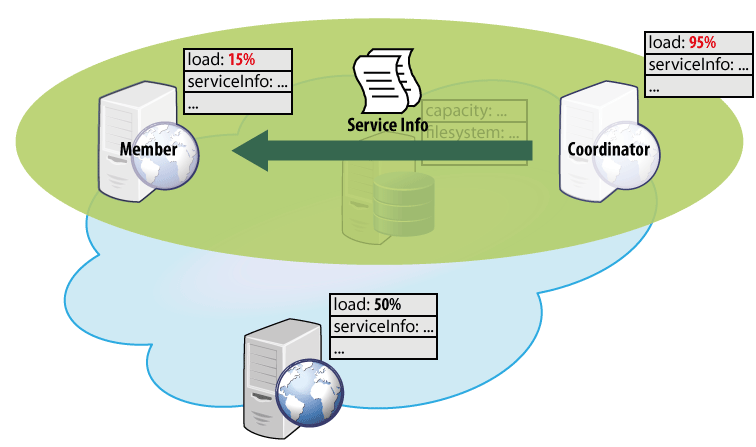
Figure 3. Application of the ensemble definition from Figure 2 to the components from Figure 1.
According to the exchange of service information, the member nodes then individually perform service migration via the external (i.e., outside of DEECo) migration mechanism.
Current Implementation & Future Vision
As for implementation, we work on a prototype based on distributed tuple spaces and implemented in Java. The sources, as well as documentation and examples, can be found at https://github.com/d3scomp/JDEECo.
We envision that the component model outlined here will serve as the basis for a design methodology that will exploit the presented abstractions and help in building long-lasting systems of service-components and service-component ensembles.
Is your software adaptive?
As business processes and software architectures have started to extend beyond the boundaries of corporate systems through the Internet, computing systems have been facing a complete new set of expectations as well as market opportunities. Not only there has been an increasing complexity to be met for guaranteeing that the offered networks and services are trustworthy, but the need of designing and implementing open, loosely coupled services has come together with rapidly changing requirements to be met, with severe time-to-market constraints to be met and with unpredictable service compositions to be anticipated. In principle, autonomic systems are the best answer to these challenges, because they are capable to self-adapt to changing scenarios. In practice, there is no common agreement in the literature on what makes a system be adaptive, so that autonomic systems can be engineered under completely different and possibly conflicting strategies and operating guidelines.
Self-adaptive systems have been widely studied in several disciplines ranging from Biology to Economy and Sociology and there it is widely accepted that a system is self-adaptive if it can modify its behaviour as a reaction to a change in its context (e.g., the environment, the knowledge accumulated). But the problem with such definition emerges during the translation to the Computer Science setting, because it becomes too ambiguous to be helpful in discriminating adaptive systems from non-adaptive ones. In fact, most programs can change behaviour (as they can execute conditional statements, handle exceptions, etc.) as a reaction to a change in their context (as they can input data, modify parameters, etc.). And then, must an adaptive system always be capable to react to any change? Or does it suffice that it may adapt to some changes? Typically the behaviour is changed to improve some measure of performance or degree of satisfaction, but there can be no warranty about that, so what if the opposite happens? Does a system that decreases its performance deserve to be called adaptive?
As an example, consider the scenario of a speaker at a meeting that wants to connect her notebook to the beamer for given her presentation. The software of the notebook and of the beamer has been designed separately, without knowing which kind of beamer (resp. notebook) will be connected to, an agreement must be found for choosing the resolution at which the beamer will work and it is maybe the case that the resolution of the screen of the laptop will change as a consequence. Given these premises, one is lead to conclude that beamer and the notebook are adaptive systems. But what if we are told that the beamer is controlled by a loop that tries to synch with the notebook, starting from the highest resolution to lower ones until a common resolution is found? Isn't this just a default behaviour? Would you still call the beamer adaptive? And the notebook?

As a more interesting example, take the swarms of robots studied in the ASCENS case studies and one of the many challenging adaptation scenarios, like the hill crossing one, where the robots must self-assemble
if they encounter a hill to steep to climb alone. Looking at one of the video demo is impressive: the robots try and fail several time until they finally succeed (or maybe some robots is left alone behind). There is little doubt in calling the software of the robots (self-)adaptive. Still, a closer look at the so-called basic self-assembling strategy they run reveal a finite state machine controlling the adaptation strategy, not much different than a few conditional statement in a program in the end.
Puzzled by the above examples and many similar ones, we have come to the conclusion that the main problem with definition given above is that it relies on a black box view of the system, where an observer tries to classify the system without looking at the software it runs. This is reasonable in many other fields where adaptive systems have been studied, like Biology, because we cannot have a direct look at the "software" and we need to guess it. But the assumption is no longer valid in software systems, especially when the designer perspective is taken, not the user one.
The ambiguity becomes less striking when we take a white boxview of the system. In fact, many architectural approaches to autonomic systems take radically different guidelines on the way they can be structured or composed and on the way they operate. However, in most cases, such approaches are prescriptive: they take an underlying principle and explain how to build autonomic system according to that principle. For example, in the FORMS approach (FOrmal Reference Model for Self-adaptation) reflection is taken as a necessary criterion for any self-adaptive system: roughly, it must be capable to represent and manipulate a meta-level description of itself / of its behaviour. In the MAPE-K approach a self-adaptive system is made of a component implementing the application logic, equipped with a control loop that Monitors the execution through sensors, Analyses the collected data, Plans an adaptation strategy, and finally Executes the adaptation of the managed component through effectors; all the phases of the control loop access a shared Knowledge repository. While FORMS and MAPE-K are not necessarily conflicting, they suggest diverging architectures: in the case of MAPE-K, a strictly hierarchical structure is recommended, where the application logic of one layer implements the adaptation logic of the layer below and the two are to be kept well separated; in the case of FORMS it is favoured a mixture of application logic and adaptation logic by the use of reflection at the level of the application logic.
In a recent work we have proposed an architecture-agnostic, conceptual framework for adaptation, where the white box view of the system is essential. The crux of the framework is that the decision of whether a system is adaptive or not is a relative matter, not an absolute one.
According to a traditional paradigm, a program governing the behaviour of a component is made of control and data : these are two conceptual ingredients that in presence of sufficient resources (like computing power, memory or sensors) determine the behaviour of the component. In order to introduce adaptivity in this framework, we require to make explicit the fact that the behaviour of a component depends on some well identified control data, without being prescriptive on the way it is marked as such. Then: we define adaptation just as the run-time modification of the control data; we say that a system is adaptive if its control data are modified at run-time, at least in some of its executions; and we say that a system is self-adaptive if it is able to modify its own control data at run-time.
Ideally, a sensible collection of control data should be chosen to enforce a separation of concerns, allowing to distinguish neatly, if possible, the activities relevant for adaptation (those that affect the control data) from those relevant for the application logic only (that should not modify the control data). Then, any computational model or programming language can be used to implement an adaptive system, just by identifying the part of the data governing the behaviour. Consequently, the nature of control data can greatly vary depending on the degree of adaptivity of the system and on the computational formalisms used to implement it. Examples of control data include configuration variables, rules (in rule-based programming), contexts (in context-oriented programming), interactions (in connector-centred approaches), policies (in policy-driven languages), aspects (in aspect-oriented languages), monads and effects (in functional languages), and even entire programs (in models of computation exhibiting higher-order or reflective features).
So, coming back to the question posed in the title of this post, if you need to decide if you software system is adaptive or not, you need to name your control data first, then the rest will follow.