Knowledge Representation for Autonomic Behavior
A cognitive system is considered to be a self-adaptive system that changes its behavior in response to stimuli from its execution and operational environment. Such behavior is considered autonomic and self-adaptive and is intended to drive a system in situations requiring adaptation. Any long-running system is subject to uncertainty in its execution environment due to potential changes in requirements, business conditions, available technology, etc. Thus, it is important to capture and cater for uncertainty as part of the development process. Failure to do so may result in systems that are too rigid to be fit for purpose, which is of particular concern for the domains that typically make use of self-adaptive technology, e.g., ASCENS. We hypothesize that modeling uncertainty and developing mechanisms for managing it as part of Knowledge Representation & Reasoning (KR&R) will lead to systems that are:
- more expressive of the real world;
- fault tolerant due to fluctuations in requirements and conditions being anticipated;
- flexible and able to manage dynamic changes.
Formal Approach
The ability to represent knowledge providing for autonomic behavior is an important factor in dealing with uncertainty. In our approach, the autonomic self-adapting behavior is provided by policies, events, actions, situations, and relations between policies and situations (see Definitions 1 through 8). In our KR&R model Policies (Π) are responsible for the autonomic behavior. A policy π has a goal (g), policy situations (Siπ), policy-situation relations (Rπ), and policy conditions (Nπ) mapped to policy actions (Aπ), where the evaluation of Nπ may imply the evaluation of actions (denoted with Nπ→Aπ) (see Definition 2). A condition is a Boolean function over ontology (see Definition 4) or the occurrence of specific events or situations in the system. Thus, policy conditions may be expressed with policy events. Policy situations (Siπ) are situations (see Definition 6) that may trigger a policy π, which implies the evalua-tion of the policy conditions Nπ (denoted with Siπ→π→Nπ). A policy may also comprise optional policy-situation relations (Rπ) justifying the relationships between a policy and the associated situations. The presence of probabilistic belief in those relations justifies the probability of policy execution, which may vary with time. A goal is a desirable transition from a state to another state (denoted with s⇒s') (see Definition 5). A situation is expressed with a state (s), a history of actions (Asi←) (actions executed to get to state s), actions Asi that can be performed from state s and an optional history of events Esi← that eventually occurred to get to state s (see Definition 7).

Ideally, policies are specified to handle specific situations, which may trigger the application of policies. A policy exhibits a behavior via actions generated in the environment or in the system itself. Specific conditions determine, which specific actions (among the actions associated with that policy – see Definition 2) shall be executed. These conditions are often generic and may differ from the situations triggering the policy. Thus, the behavior not only depends on the specific situations a policy is specified to handle, but also depends on additional conditions. Such conditions might be organized in a way allowing for synchroniza-tion of different situations on the same policy. When a policy is applied, it checks what particular conditions are met and performs the associated actions (see map(Nπ,Aπ) – see Definition 2). The cardinality for the policy-situation relationship is many-to-many, i.e., a situation might be associated with many policies and vice versa. Moreover, the set of policy situations (situations triggering a policy) is open-ended, i.e., new situations might be added or old might be removed from there by the system itself. With a set of policy-situation relations we may grant the system with an initial probabilistic belief (see Definition 2) that certain situations require specific policies to be applied. Runtime factors may change this probabilistic belief with time, so the most likely situations a policy is associated with can be changed. For example, the successful rate of actions execution associated with a specific situation and a policy may change such a probabilistic belief and place a specific policy higher in the "list" of associated policies, which will change the behavior of the system when a specific situation is to be handled. Note that situations are associated with a state (see Definition 7) and a policy has a goal (see Definition 2), which is considered as a transition from one state to another (see Definition 5). Hence, the policy-situation relations and the employed probabilistic beliefs may help a cognitive system what desired state to choose, based on past experience.
Case Study
To illustrate autonomic behavior based on this approach, let us suppose that we have a robot that carries items from point A to point B by using two possible routes - route one and route two (see Figure 1). A situation si1:“robot is in point A and loaded with items” will trigger a policy π1:“go to point B via route one” if the relation r(si1,π1) has the higher probabilistic belief rate (let’s assume that such a rate has been initially given to this relation because route one is shorter – see Figure 1.a). Any time when the robot gets into situation si1 it will continue applying the π1 policy until it gets into a situation si2:“route one is blocked” while applying that policy. The si2 situation will trigger a policy π2:“go back to si1 and then apply policy π3” (see Figure 1.b). Policy π3 is defined as π3:“go to point B via route two”. The unsuccessful application of policy π1 will decrease the probabilistic belief rate of relation r(si1,π1) and the eventual successful application of policy π3 will increase the probabilistic belief rate of relation r(si1,π3) (see Figure 1.b). Thus, if route one continues to be blocked in the future, the relation r(si1,π3) will get to have a higher probabilistic belief rate than the relation r(si1,π1) and the robot will change its behavior by choosing route two as a primary route (see Figure 1.c). Similarly, this situation can change in response to external stimuli, e.g., route two got blocked or a "route one is obstacle-free" message is received by the robot.
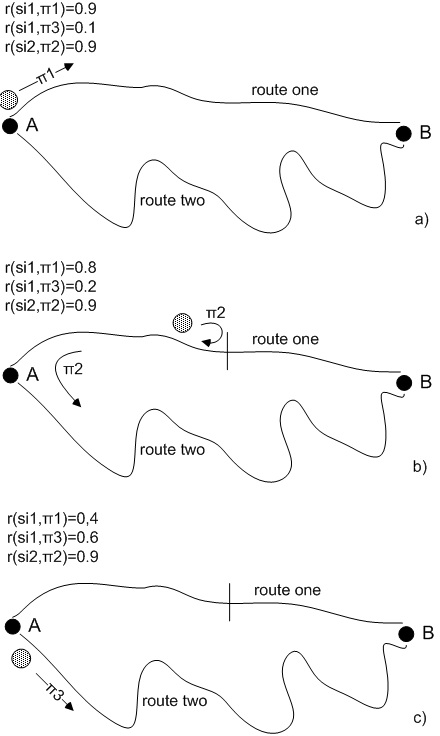
Figure 1: Self-adaptation Case Study
Knowledge Representation for ASCENS
Knowledge
When it comes to AI, we think about the knowledge we must transfer to the computerized machines and make them use that knowledge, so they become intelligent. In this regard, one of the first questions we need to answer is on the notion of knowledge. So, what is knowledge? To answer this question we should consider two facts: 1) it is known that knowledge is related to intelligence; and 2) the definition of knowledge should be given with terms from the computer domain. Scientists agree that the concept of intelligence is built upon four fundamental elements: data, information, knowledge, and wisdom. In general, data takes the form of measures and representations of the world—for example, raw facts and numbers. Information is obtained from data by assigning relevant meaning, usually by putting data in a specific context. Knowledge is a specific interpretation of information. And wisdom is the ability to apply relevant knowledge to a particular problem.
Why knowledge representation?
Intelligent system designers use knowledge representation to give computerized systems large amounts of knowledge that helps them understand the problem domain. Still computers "talk" in a "binary" language, which is simple, logical, and sound, and has no sense of ambiguity typical for a human language. Therefore, computers cannot be simply given textbooks, which they understand and use, just like humans do. Instead, the knowledge given to computers must be structured in well-founded computational structures that computer programs may translate to the binary computer language. Knowledge representation structures could be primitives such as rules, frames, semantic networks and concept maps, ontologies, and logic expressions. These primitives might be combined into more complex knowledge elements. Whatever elements they use, designers must structure the knowledge so that the system can effectively process and it and humans can easily perceive the results.
Many conventional developers doubt the utility of knowledge representation. Fact is that knowledge representation and the accompanying reasoning can significantly slow a system down when it has to decide what actions to take, and it looks up facts in a knowledge base to reason with them at runtime. This is one of the main arguments against knowledge representation. Why not simply “compile out” the entire knowledge as “procedural knowledge”, which makes the system relatively faster and more efficient. However, this strategy will work for a fixed set of tasks, i.e., procedural knowledge will give the system the entire knowledge the system needs to know. However, AI deals with an open set of tasks and those cannot be determined in advance (at least not all of them). This is the big advantage of using knowledge representation – AI needs it to solve complex problems where the operational environment is non-deterministic and a system needs to reason at runtime to find missing answers.
Knowledge Representation for ASCENS
ASCENS is an AI project tackling self-adaptation of systems operating in open-ended environment, e.g., our physical world. Such systems need to be developed with initial knowledge and learning capabilities based on knowledge processing and awareness. It is very important how the system knowledge is both structured and modelled to provide essence of awareness. We propose a special multi-tier knowledge structure, allowing for knowledge representation at different depths of knowledge.
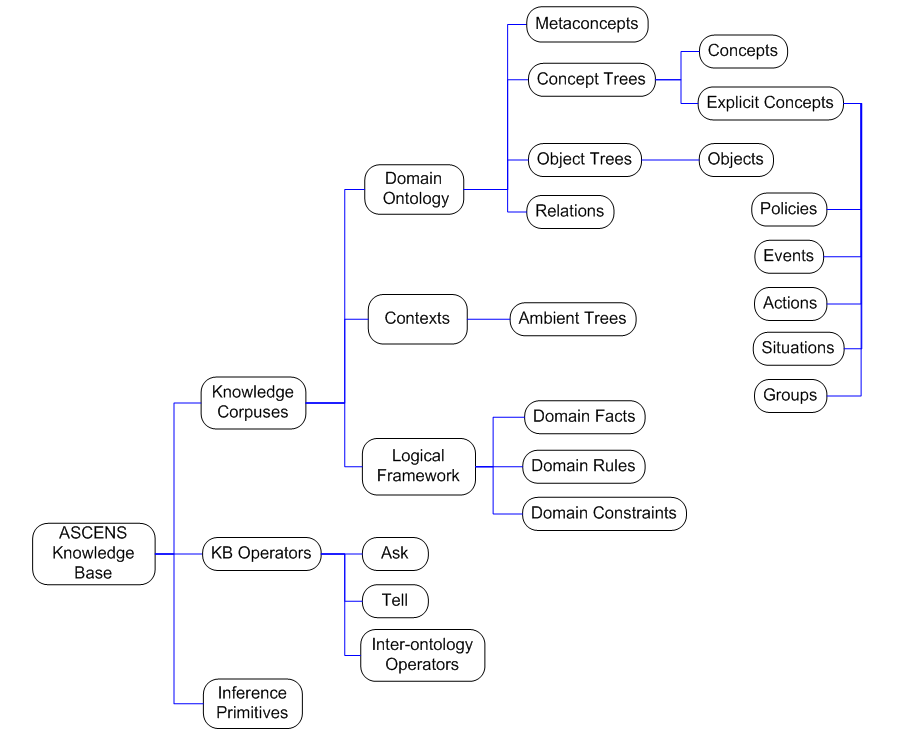
ASCENS Knowledge Model
ASCENS in Quest of Awareness-Rich Technology
The ASCENS project aims at bringing awareness into technical systems. Formalisms, linguistic constructs and programming tools should be developed featuring high level of autonomous and adaptive behavior. Rigorous and sound concepts will be used to reason and prove system properties, but how can we judge the project’s pragmatic significance? The impact and practical value of the ASCENS project results will be evaluated on e-mobility, cloud computing and swarm robotics application domains. The three novel application domains look complex and fairly different and one may ask: isn’t each problem difficult enough? Why solving all three at once?
1. What E-mobility, Cloud Computing and Swarm of Robots Have in Common?
E-mobility is a vision of future transportation by means of electric vehicles network allowing people to fulfill their individual mobility needs in an environmental friendly manner.
Cloud computing is an approach that delivers computing (resources) to users in a service-based manner, over the internet.
Swarm robotics deals with creation of multi-robot systems that through interaction among participating robots and their environment can accomplish a common goal, which would be impossible to achieve by a single robot.
At a first glance e-cars and transportation, distributed computing on demand and swarm robotics have nothing in common!
1.1 Sharing and Collectiveness
In order to cover longer distances, an e-vehicle driver must interrupt the journey to either exchange or re-charge the battery. Energy consumption has been the major obstacle in a wider use of e-vehicles. Alternative strategy is to share e-vehicles in a way that optimizes the overall mobility of people and the spending of energy. In other words: when my battery is empty – you will take me further if we go towards the same location and vice versa.
The processing statistics show that most of the time computers are idle – waiting for input to do some calculations. Computers belong amongst fastest and at the same time most wasted devices man has ever made. And they dissipate energy too. Cloud computing overcomes that problem by sharing computer resources and making them better utilized. In another words if my computer is free – it can process your data and vice versa; or even better, let us have light devices and leave a heavy work for the cloud.
A swarm indicates a great number of things in motion. Swarm robots dynamically form different shapes in order to solve a collective assignment. Swarm of robots can perform much more as a group than any single element can do on its own. In other words, what we cannot achieve alone, we may manage together.
At a closer look “sharing and collectiveness” are common characteristics of all three application domains!
1.2 Awareness and Knowledge
E-mobility can support coordination only if e-vehicles know their own restrictions (battery state), destinations of users, re-charging possibilities, parking availabilities, the state of other e-vehicles nearby. With such knowledge collective behavior may take place, respecting individual goals, energy consumption and environmental requirements.
Cloud computing deals with dynamic (re-)scheduling of available (not fully used) computing resources. Maximal utilization can only be achieved if the cloud is “aware” of the users’ processing needs and the states of the deployed cloud resources. Only with such a knowledge a cloud can make a good utilization of computers while serving individual users needs.
Each robot in a swarm needs to know its own and the others’ location and capabilities as well as an overall assignment. Only then a swarm can achieve the common goal.
At a closer look “awareness” of own potentials, restrictions and goals as well as those of the others is a common characteristic. All three domains require self-aware, self-expressive and self-adaptive behavior.
1.3 Dynamic and Distributed Optimization
E-mobility is a distributed network that manages numerous independent and separate entities such as e-vehicles, parking slots, re-charge stations, drivers. Through collective and awareness-rich control strategy the system may dynamically re-organize and optimize the use of energy while satisfying users’ transportation needs.
Cloud computing actually behaves as a classical distributed operating system with a goal to maximize operation and throughput and minimize energy consumption, performing tasks of multiple users.
Swarm robotics deals with coordination of a collection of individual robots in order to optimize control strategy through interaction among the robots and the environment.
At a closer look “dynamic and distributed optimization” is inherent characteristic of the control environment for all three application domains.
2. Again, What E-mobility, Cloud Computing and Swarm of Robots Have in Common?
Control systems for all the three domains have many common characteristics: they are highly collective, constructed of numerous independent entities that share common goals. Their elements are both autonomous and cooperative featuring a high level of self awareness and self expressiveness. A complex control system built out of such entities must be robust and adaptive offering maximal utilization with minimal energy and resource use.
3. What the three domains have to do with ASCENS Project?
Formal definition, programming and controlling of complex massively parallel distributed system that feature awareness, autonomous and collective behavior, adaptive optimization and robust functioning are grand challenges of computer science. These challenges are present in most of complex control systems and they are the motivation and inspiration for the ASCENS project. The consortium gathered scientists from different fields in effort to offer novel and scientifically sound concepts and approaches:
- SCE - service–component ensembles as means to dynamically structure independent and distributed system entities
- Modeling and formalization of the fundamental SCE properties as means to rigorously reason about autonomous behavior and aware-rich networking, proving that important system requirements hold
- linguistic support for programming SCEs, expressing awareness and exchanging knowledge among system entities
- adaptive and knowledge-rich software environments and tools, expressing and deploying self-awareness and self-expression in technical systems
(see the ASCENS project goal [http://www.ascens-ist.eu/]). Consequently three different application domains are selected to test the pragmatic significance of the envisaged project concepts and results.
4. What should be the impact of ASCENS Solutions?
The ASCENS project calls for a new generation of technical solutions (techno-sphere) that would be better integrated into our biosphere by mimicking some natural phenomena like awareness, swarm behavior and adaptation. The ultimate rationale is: our resources are not endless thus our technical innovations need to be optimized and self- and energy-aware. We cannot for ever allow ourselves a luxury of driving own cars (on a global earth with increasing population and decreasing energy resources); we cannot for ever allow ourselves the luxury of switching on powerful computers that waste energy without doing much processing. We cannot neglect the usefulness of a swarm behavior (so much present in the nature) that teaches us how simple element can perform complex endeavor in a collective effort. The nature obviously achieves perfection through simplicity. Can we mimic that?
As you do not buy a cow when you need milk, you do not need to possess a car if you want to have free mobility; you do not require a powerful computer if you have processing necessities, you do not need a complex robot if you want automatic assistant. We should be oriented to hire and be charged per use rather than to buy and possess things as this may be a proper way to optimize the use of our precious resources.
To make such a mental and behavioral transition we need better control systems. We hope the ASCENS approach with its generic solutions for a wide class of applications, is a grand step in this direction.
Why is it useful to describe e-mobility using service component ensembles (SCE)?
Own Car versus Mobility Service
In a future e-mobility-scenario, it is assumed that many people don’t have their own cars. They will use vehicles temporally depending on their mobility needs. Why this assumption?
There are many of reasons for this development. All of these reasons are closely related to energy constraints and hence to the battery. The limited capacity of the battery leads to range limitation. The necessary charging time reduces the e-car availability. The high battery cost makes the car expensive and the life cycle of battery limits the time value of the vehicle. Through these arguments it can be seen that user will value mobility more than the e-vehicles itself.
Temporal Composition of Service Component Ensembles

From this point of view it is interesting to apply flexible service architectures for supporting the user. The scenario components “user” (blue colored in the figure) and “vehicle” (green colored) are no longer strongly connected in this e-mobility scenario. The scenario components are represented by their service components, which are acting as components in the user-vehicle-infrastructure network. All service component types are temporally connected for trips or sequences of trips (journeys). Additional infrastructure service components (yellow colored) assist by searching charging stations or route planning. In this view trips (A, B, C) in a journey are the constructors of service component ensembles (SCE).
Cloud Application Architectures
Infrastructure cloud services offer very powerful capabilities to utilize infrastructure resources in a very dynamic model. Instead of having minimum usage periods of month or even years the usage can be limited to only a couple of hours. These capabilities allows an application to dynamically adjust the infrastructure usage to the current requirement, but it also requires the application to be compliant to some cloud architecture principles. In this post we will briefly describe the different application architectures and also discuss the up- and downsides.
Basic requirements
In addition to the application architecture compliance also the some requirements must be met by the application in order to make the use of an infrastructure cloud as the basic infrastructure useful. From the following requirements at least one criteria must be met by the cloud application: dynamic scalability, broad network access, high failover requirements. If none of these requirements for the application in question is given the infrastructure cloud is not an appropriate runtime environment.
The requirement to dynamically scale an application can be driven from different sources. Many applications require different amounts of infrastructure due to the business logic (e.g. in the case of scientific calculations) or the user interaction (e.g. in the case of web-applications).
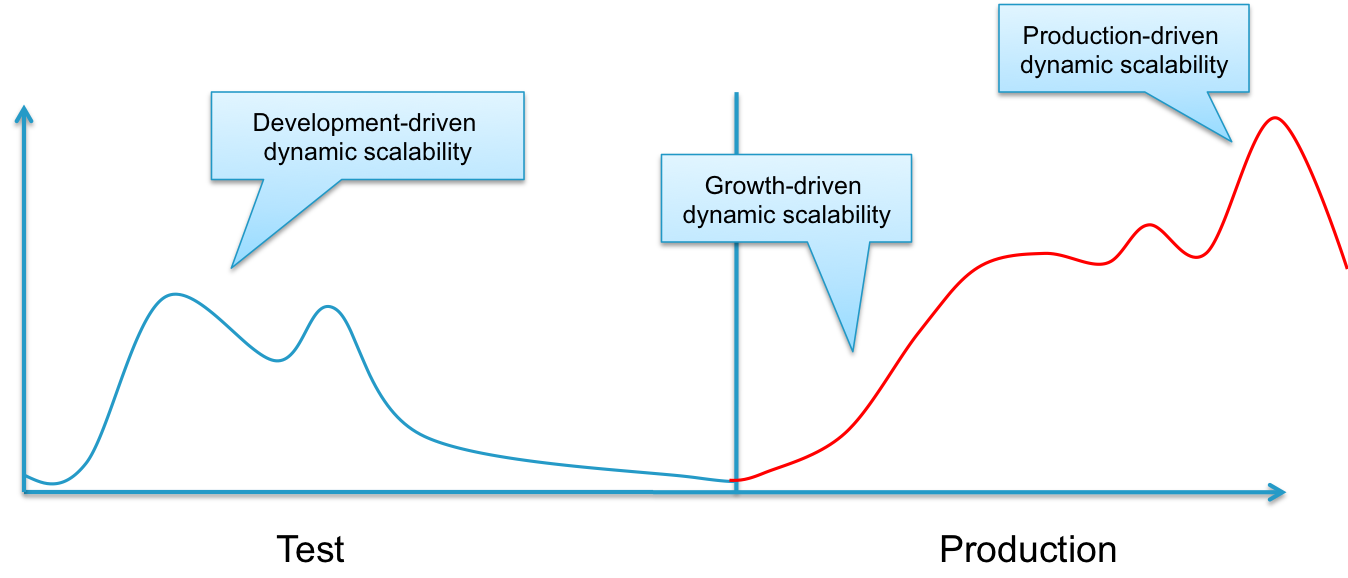
Furthermore along the entire lifecycle of an application the requirement for dynamic ressources is triggered differently as depicted in the figure above.
Broad network access is often required for applications that are accessed by a huge number of users from different networks. In this case the positioning of the application in the cloud makes the access simpler to realize and more secure.
Finally the cloud can help to create a very high availability. When using deploying single applications with multiple tiers across a set of decoupled datacenters the availability of the application can be raised to a higher level, as the combined risk (of both datacenters failing at the same time) is the multiplication of the individual risks.
Architectural Principles
After having reviewed the basic requirements for an application to be usefully deployed within the cloud this section reviews principles of application architectures that can help an application to make use of the cloud capabilities.
There are two main aspects: state management and scalability. The following table shows how these principles
Stateful vs. Stateless:
Stateful systems have substantial information on the current state of the application in the memory, or in a cache that cannot be recovered when the system is being restarted. Stateless systems in turn are keeping as little data as possible within a non-recoverable repository. Usually stateless applications are persisting all of their data instantly and keep very little information “in-flight”. Stateless systems have the huge advantage that recovery processes are much simpler. When a stateless system needs to be restarted after an uncontrolled stop it can simply restore the state from the data repository. If the system is developed in a very clean stateless way there is even no such thing like a recovery process as every operation starts without an initial state and thus takes the input values from the data repository. Therefore stateless systems have less rigid requirements for the underlying infrastructure.
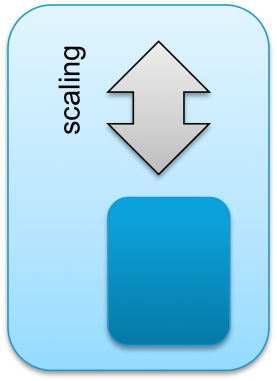
Vertical vs. Horizontal
Application design can also fundamentally differ in the way scalability is designed. An application can be either scaling up or scaling out. Scaling up means increasing the performance of a single operating system to support the higher demands of the application. Scaling out means adding additional operating system and application instances for instance in a cluster and the application will coordinate the load distribution. Typical examples of scale out architectures are webserver clusters that serve a single website.
The two scaling principles are depicted in the figure below.
| Figure | Description |
|---|---|
 |
Scaling is done by increasing single instances:
Operating System handles the additional resources transparent to the application. |
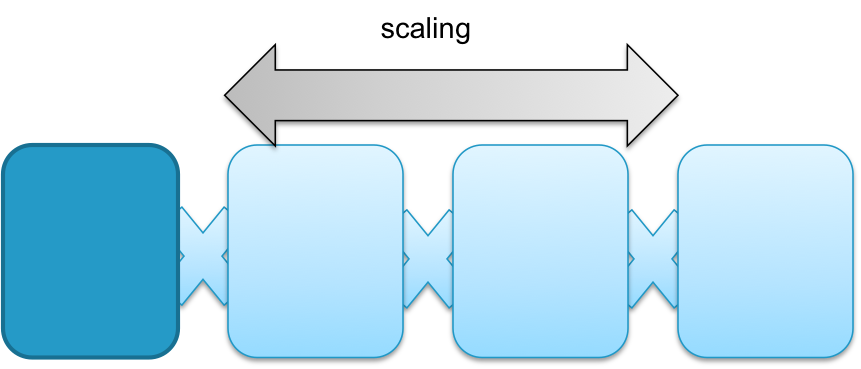 |
Scaling is done by increasing the amount of instances:
Application handles the load independent from the operating system. |
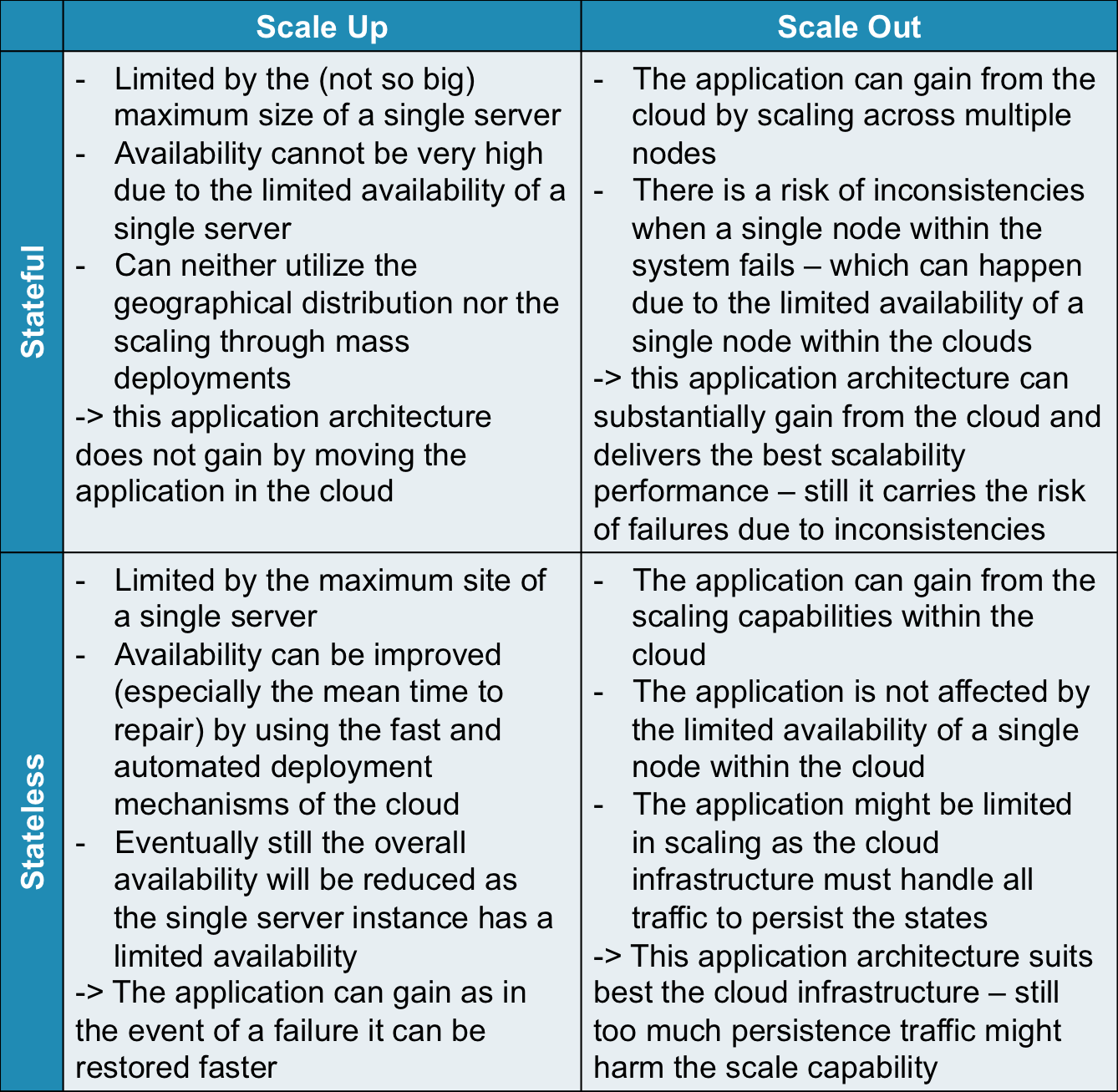
Both scalability designs have advantages and disadvantages. A short comparison can be found in the table below.
| Scale Up | Scale Out |
|---|---|
|
|
When looking the two different aspects (state management and scalability) in a combined way many applications that scale out are following the principles of statelessness, whereas many scale-up applications contain much more state within the application.
The application architecture for the cloud
How to derive from the requirements and the architectural principles a design decision for the cloud? First the physical design of the infrastructure clouds has to be reviewed briefly.
Infrastructure clouds are often build using standard sized X86 servers, each server neither being very powerful nor having a particular high availability. The power of the cloud comes from the huge mass of similar servers that are combined in a single cloud. This cloud can be within one datacenter or even across multiple locations. The later setup can often be found when the size of the cloud makes it difficult to install all servers and storage pools within one datacenter.
The following table shows how the principles match the infrastructure setup and how they support the requirements.
So in conclusion for the application architecture the cloud requires a scale out architecture. The state management of the application depends on a trade-off between the consistency requirement and the scalability requirement. Many cloud applications follow a partially stateless model - with the important data being persisted instantly whereas other data elements are not persisted and will be lost in the case of a failure of a single node.
Robot Swarms – What can formal methods do?
Previous posts of this blog (see Ensembles and mobile robots, where is the link? and Robot Swarms – What can they do?) have convinced us that the swarm robotics case study is of great interest and importance to the ASCENS project. In fact, on the one hand, swarm robotic systems comfortably fit to the ASCENS notion of ensemble and, on the other hand, the lack of formal tools for designing, controlling and reasoning on such systems poses a major challenge to the ASCENS researchers. To meet this challenge, we intend to devise new formal methods and approaches capable of dealing with the distinctive aspects and the complexity of swarm robotic systems and, more in general, of autonomic service-component ensembles.
But what can formal methods actually do? We don't aim at providing here an exhaustive answer to this question, by making e.g. a tedious list of approaches, techniques and tools that we plan to use and/or develop in ASCENS. This post indeed wants to give just a taste of the use of formal methods in this setting. In particular, we present below a result of our first attempt at formalizing and analyzing a scenario of the ASCENS robotics case study.
The following video shows a (stochastic) simulation, based on the use of the language Klaim and some related tools, in which three robots are in charge of collectively transporting an object to a goal area.
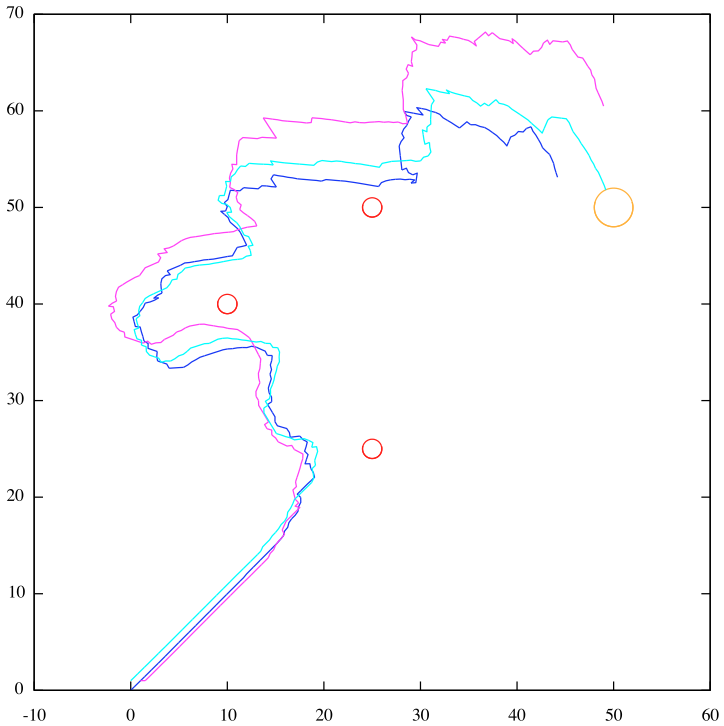
Robotics scenario in Klaim: result of a simulation (VIDEO)
Initially, the robots start moving towards the goal (i.e. the big circle in the upper-right corner). As soon as an obstacle enters into the range of their distance scanners, the robots change their directions and pass over the obstacle. This way, they reach without collisions the goal.
A formal study of such systems offers many advantages with respect to an experimental evaluation. Indeed, the latter approach is usually costly to organize, time consuming, incomplete and, sometimes, prohibitive in the design phase. Instead, a formal approach enables the exploration of several different situations and the prediction of the systems behavior.
Robot Swarms – What can they do?
Swarm robotics has been chosen as one of the three case studies of the ASCENS project. But why are robot swarms interesting, and why are they a useful case study for the ASCENS project? Our contention is that for many real-world problems, it is often more effective to use large cooperating teams of simple, cheap robots than to use a single complex robot. In Nature, ants can build complex nests that are orders of magnitude larger than a single ant, and whose construction lasts many ant lifetimes. Similarly, we envision future swarms of robots performing tasks autonomously, in a robust parallel way.
In the following video, a group of robots team up to transport an object that is too heavy for a single robot to move. Note that the control is distributed - the designer of the system set up simple rules to ensure that the robots would cooperate to move the object. But the rules are set up in such a way that the number of robots doesn't need to be specified in advance. So the same control could be used with two robots, or a hundred robots. And the control would still work if two robots happen not to boot up at the start of the experiment. The video was taken from experiments conducted in the swarm-bots project (http://www.swarm-bots.org), which concluded in 2005. In the Ascens project we will be using a robot with a similar form factor, but with much more advanced sensors, actuators and computational abilities (see previous post http://blog.ascens-ist.eu/2011/03/ensembles-and-mobile-robots-what-is-the-link/).
This kind of distributed control has the potential to provide flexible, robust systems. The problem is that to date, swarm robotic systems tend to be designed in an ad-hoc fashion, based largely on the intuition of the system designer. It is very hard to predict in advance what such systems will do, or to be able to provide any formal guarantees about their behaviour. By the end of the ASCENS project, we hope to have some interesting solutions to this problem.
Dreaming of fluffy clouds
Clouds. For a while now I've been under impression that they are present virtually everywhere. Even on beautiful sunny days in spring people seem to be fascinated by clouds. What do they see in them, I wonder. It is the extensive media coverage they receive, which suggests that they might be an important trend in computing. But how do they affect me and my every day life?
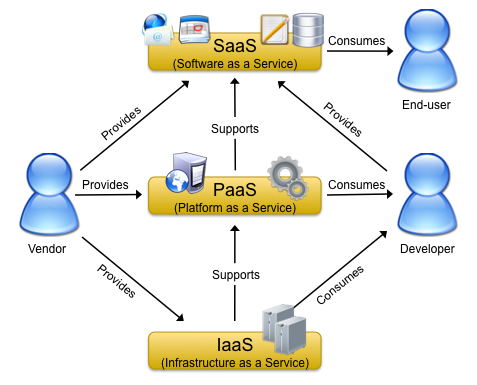
A variety of attempts has been made to describe and characterize cloud computing from different points of view. The generally agreed upon idea behind this concept is the provisioning of services and IT-resources in a dynamic and on-demand way over the Internet, backed by different billing models, such as subscriptions or pay-as-you-go. This definition is quite broad and does not limit cloud computing to certain types of services or IT-resources. Yet, today we typically associate cloud-based products with one of three categories, which address infrastructure, platform and software needs.
The following image is based on a publication by Briscoe and Marinos ("Digital Ecosystems in the Clouds: Towards Community Cloud Computing") and presents a view on these three types of clouds with the relationships among them and between vendors and users.
- Infrastructure-as-a-Service (IaaS) is concerned with the provisioning of storage and processing power, the latter of which is typically implemented and provided in terms of so-called virtual machines. A virtual machine is a computer that is simulated on top of a phyiscal machine and that can be fully configured by the user, (virtual) hardware- and software-wise. IaaS can support ...
- Platform-as-a-Service, which is a means of providing an execution platform for user-provided applications in the cloud. Although not as customizable as IaaS clouds, PaaS clouds typically have the benefit of providing a simple and efficient way for the implementation of application for the Internet. They form an abstraction layer over actual (physical or virtual) machines and can thereby provide a developer-friendly ecosystem for application development and deployment. Based on such a platform, vendors and users may provide ...
- Software-as-a-Service. Actual products for end-users, such as e-mail and calendars, but also web-based document processing or image mangement. Think Google Apps and Microsoft Office Live, just to give to examples of SaaS cloud services, although most other Web 2.0 products may as well be categorized as SaaS.
 Since its inception, cloud computing has been established as a viable alternative to traditional in-house provisioning of IT-resources and is continously gaining more acceptance and use in both personal and corporate environments. It enables companies to outsource their infrastructure and service needs, to save investments in local computing resources and the management thereof, and to react to changing requirements more flexibly since cloud resources can be requested and used on demand.
Since its inception, cloud computing has been established as a viable alternative to traditional in-house provisioning of IT-resources and is continously gaining more acceptance and use in both personal and corporate environments. It enables companies to outsource their infrastructure and service needs, to save investments in local computing resources and the management thereof, and to react to changing requirements more flexibly since cloud resources can be requested and used on demand.
However, with the use of these public clouds, as offered by Amazon, Microsoft and Google, to name some of the big providers, companies incur a dependency on these external providers. The reliability of their service provisioning is a critical factor for the continuing success of the company and is typically detailed in service level agreements between the provider and the consumer among other quality-of-service characteristics.
Nevertheless, cloud computing outages have caused severe problems in the past with service and infrastructure down-times ranging from a few minutes to multiple hours, as illustrated by Alex Williams in his article "Top 5 Cloud Outages of the Past Two Years: Lessons Learned". Today the analysis and repair of these problems is typically performed by human operators, which makes it difficult to predict the time required for the reestablishment of cloud availability to normal levels or to levels as specified in service level agreements. In order to be able to provide robust cloud services it is therefore necessary to automate at least large parts of these analysis and repair steps.
In the ASCENS project we pursue this goal by introducing a sense of self-awareness to clouds to enable autonomous reactions to changes in the infrastructure, such as the abrupt departure of computation nodes, to give an example. By enabling autonomous reactions, we seek to be able to deliver more robust cloud services with higher quality-of-service levels. This idea of self-healing systems is something we think is vital for delivering reliable cloud services as it transfers the responsibility of fault analysis and repair from human operators to machines, which are able to perform these actions in shorter time spans thereby reducing potential downtimes of services and improving customer satisfaction.
Clouds. The vision of making data and services accessible from anywhere at any time is very appealing and fits in perfectly with our changing lifestyle and higher mobility. Music, movies, documents, pictures, ... No longer are we limited by the fact that these artifacts are stored locally on some machine that we first need to switch on in order to gain access. Our data and important services, such as e-mail and calendars, live in the Cloud and are available to us on desktop computers, notebooks, smartphones and other portable devices. At the same time we incur a dependency on being connected to the Internet and to our cloud providers. If the provider is not able to service our requests, well, then we are blocked from accessing our data. It is therefore crucial that cloud services are robust and highly-available. This is what we strive for in the ASCENS project.
Ensembles and mobile robots, where is the link?
Mobile robotics systems are complex artifacts composed of dozens of sensors, actuators, processors, processes, behaviors and even robots, if we consider robotic swarms. Mobile robots evolve mostly in complex unpredictable environments, interact with objects, infrastructures or even humans. Designing and controlling such systems and predicting their performances is a real challenge, where formal design tools are drastically missing. One goal of ASCENS is to provide the theoretical foundations and the technical tools to perform this design.
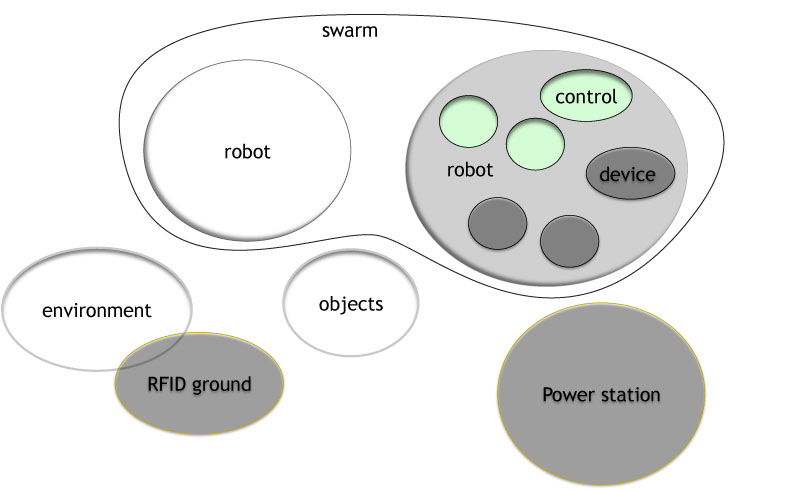
What is the link of this with ensembles? As mentioned in the first post of this blog: "Ensembles are software-intensive systems with massive numbers of nodes or complex interactions between nodes, operating in open and non-deterministic environments in which they have to interact with humans or other software-intensive systems in elaborate ways.". In robotics we can consider several types of nodes, depending on the level of abstraction one chooses. The hardware modules (intelligent sensors and actuators) of a robot can be considered as nodes within a single robot, interacting through a interconnection bus. Basic controlling behaviors that are combined to achieve the global behavior of a robot can also be considered as nodes, at a more abstract level. Abstracting even more, robots in a swarm can be considered as nodes within the swarm ensemble. One can even consider all these nodes simultaneously, building a hierarchical structures of nodes. This creates a massive number of nodes, fitting to the ensembles definition given above. The interactions between these nodes are complex, because of the complexity of the structure, of the global result and of the environment. The type of environment where robots evolve is non-deterministic and can include interaction with humans or others robots / artifacts, fitting again to the ensemble definition given above.

Therefore swarm robotics has been chosen as one of the three case studies of the ASCENS project. The robots used in this case-study is the marXbot, developed at EPFL. The marXbot has an internal distributed architecture, called ASEBA. The marXbot can interact with other robots, even physically by self-assembling in a bigger entity. Finally the marXbot supports interaction with specific environment systems, such as an RFID ground. Because of this large set of features, the marXbot robot is the ideal platform to implement and validate the concepts developed within ASCENS. Stay tuned for astonishing new approaches to robot control design!
What are Ensembles? And Why Should I Care?
Our goal in ASCENS is to build "Autonomic Service-Component Ensembles"—sounds nifty (or so we thought), but what does it actually mean?
A Little Bit of History
The meaning for "ensemble" that we use in ASCENS was coined in the InterLink project's work group on software-intensive systems and new computing paradigms, somewhere around 2007. In this group we all agreed that many systems that we will be building in the next decades will share a number of important properties. But none of the terms in current use—software-intensive systems, cyber-physical systems, etc.—seemed to really differentiate the entities we were talking about from those we were not particularly interested in. At some point Seth Goldstein suggested the name "ensembles" for the kinds of complex, networked cyber-physical systems we were discussing and it proved to be an instant hit in our group. When writing up the report for our workshop I needed a word for "ensembles which are not cyber-physical systems", so I hijacked Seth's term for this more general concept and used physical ensembles for the original meaning.
Well, then, the million dollar question is:
What are Ensembles?
Glad you asked. Ensembles are software-intensive systems with massive numbers of nodes or complex interactions between nodes, operating in open and non-deterministic environments in which they have to interact with humans or other software-intensive systems in elaborate ways. Ensembles have to dynamically adapt to new requirements, technologies or environmental conditions without redeployment and without interruption of the system’s functionality, thereby blurring the distinction between design-time and run-time.
More catchy but less precise: ensembles are these systems where we currently know neither how to specify them nor how to build them. Wait a moment—there are systems that satisfy the definition of ensembles that have successfully been built. What about Google's infrastructure? What about the German LKW-Maut system?
The Good, the Bad, and the Lucky
Google's services definitely can be considered as an ensemble, and in fact cloud computing is one of the case studies in ASCENS. Why do we then claim that we don't know how to build ensembles? Well, Google's infrastructure, consisting of several clusters with hundreds of thousands or even millions of servers, is massive any way you look at it. But it is mostly used to scale (more or less) well-understood tasks with simple user interactions to unimaginably large data sets and numbers of transactions. Google as well as other "internet-scale" companies had to come up with clever solutions to overcome scalability problems, and this is probably one area of ensemble engineering where we will see a lot more progress in the future. But still, leaving aside the algorithmic problems of search, the problem of dealing with huge amounts of data, and some other trivialities (and thereby ignoring everything that makes Google tick...) the basic problem a search engine faces is building an index and looking up keywords in this index. So, yes, it is actually possible to build ensembles, at least for some of the simpler scenarios. If you want to be successful with that, it's probably a good idea to follow in Google's footsteps and focus on ensembles where the main problems are algorithms and scalability. And to hire some of the brightest minds in computer science to do it. It doesn't hurt to build better web interfaces than anybody else and to revolutionize our understanding of what web apps make possible, as they did with Google maps. And to generally do no evil.
Easy as pie. But just in case you weren't planning on following these steps, take care. Things can blow up in your face real quick.
Let's look at the German LKW-Maut system, the automated billing for truck's usage of motorways. The one good thing that can be said about that project is that it was finally completed. But it's not the kind of project you want to base your career on: The tender was accepted on September 20, 2002 with an expected completion date of August 31, 2003, one year later. After many troubles and changes in consortium management, the system started in a limited manner on January 1, 2005 and reached its full capabilities on January 1, 2006—more than 3 years after it started—with billions of Euros lost in expected revenue and with liquidated damages of 1.6 billion Euros. While this is a somewhat extreme example, large delays, cost overruns and systems that fulfill only a part of their original requirements are not at all uncommon when we try to build complex software systems using current development methods.
So the question is: How can we find reliable ways to build these kinds of systems? And what's the best way to build ensembles so that we can have confidence that they actually do what we want them to do?
And there is more: Google and the LKW-Maut system both work in relatively well-known environments with slowly changing requirements and infrastructure. What happens when you change to more dynamic scenarios? For example, what if you wanted to dynamically distribute the joint computing power of several universities to research projects in a "research grid"? How can we ensure that the distribution is fair to everybody involved? How do we deal with parts of the research grid suddenly becoming unavailable because of network problems or a power outage? What if the part that failed was the master node of a map-reduce operation? How do we discourage free riders that use too many resources of others without contributing anything of their own? How do we ensure that confidential data is only processed on authorized nodes?
These are fascinating questions, and we're lucky to be funded to investigate them in ASCENS. Stay tuned as we'll report on our progress.