On Detecting Significant Changes In Performance
Embedded in the very nature of adaptive systems is the ability to react to change - whenever there is a significant change in the parameters of the system or the surrounding environment, an adaptation is triggered. Common performance parameters, such as throughput or latency, are often among the triggers - however, deciding whether the observed change in performance is significant enough to warrant an adaptation is not an easy task.
To illustrate the difficulties, consider the ASCENS Cloud Case Study. A cloud application would often exhibit decreasing performance when faced with excessive workload - and an adaptive cloud application would react to this situation by allocating more processing capacity from the cloud. We pick one such application - an example XML processing server - and look at how such reactive adaptation works.
Our adaptation mechanism measures the request processing time and when the time exceeds a threshold, it launches a new XML processing server instance. From early testing, we know that the server should exhibit an average request processing time of around 100 ms. We use this average plus some slack to set the threshold - but when we deploy the application, the very first request processing time we collect is over 900 ms, well above even a very liberal threshold!
Obviously, the very first request cannot represent an excessive workload. We therefore turn to another obvious explanation, declaring the initial measurement distorted and therefore invalid. It is common to collect multiple measurements to filter out distortions, however, we cannot wait for too many measurements because that would increase the reaction time. We start with 30 measurements: 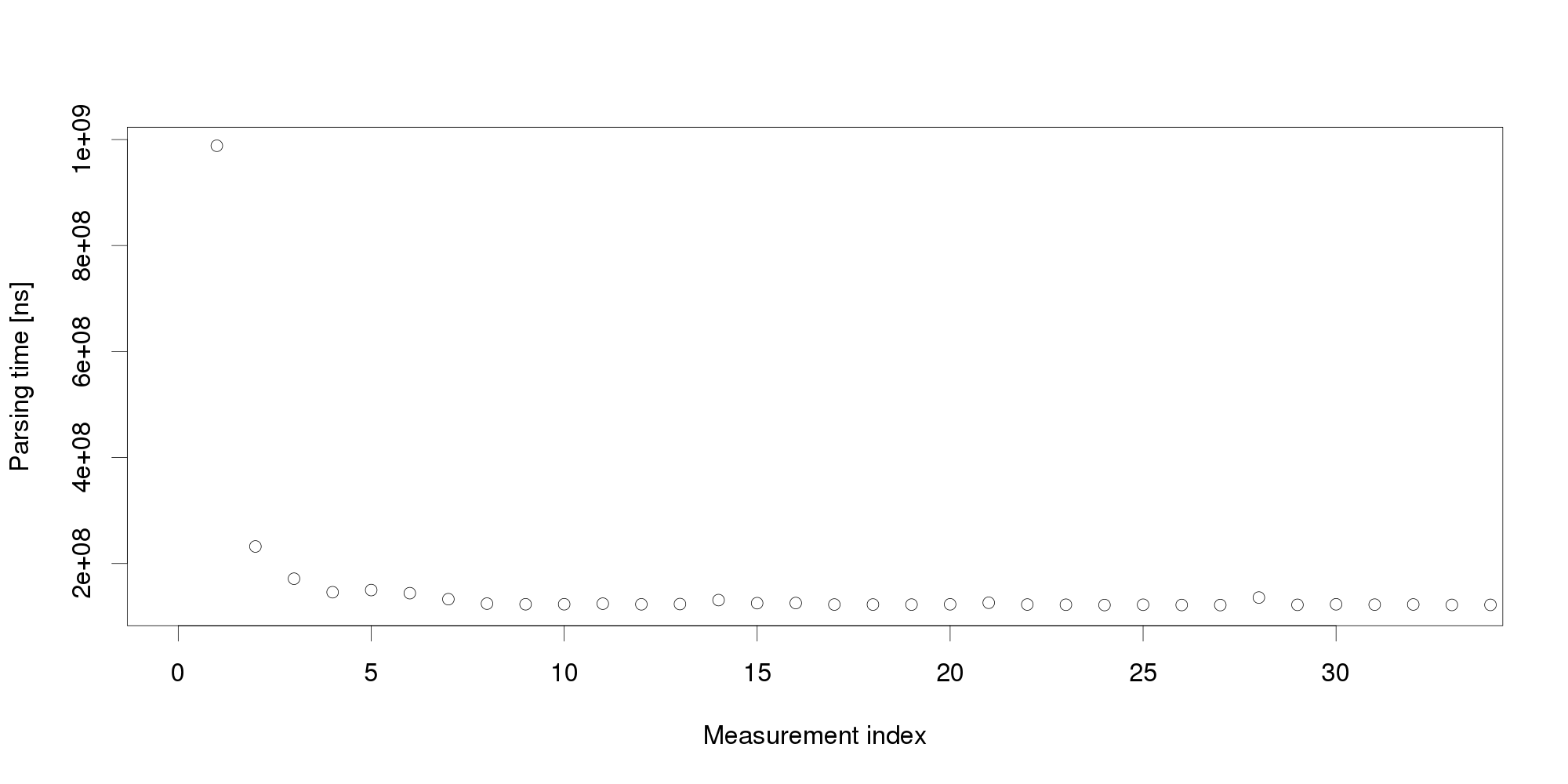
By looking at the graph, we can conclude that the measurements become stable after 5 observations. The remaining values differ very little and appear a suitable input for triggering adaptation. But collecting more measurements dispels this impression: Pursuing the same line of thought, we can conclude that performance is not as stable as we originally thought, and add even more measurements:
Pursuing the same line of thought, we can conclude that performance is not as stable as we originally thought, and add even more measurements: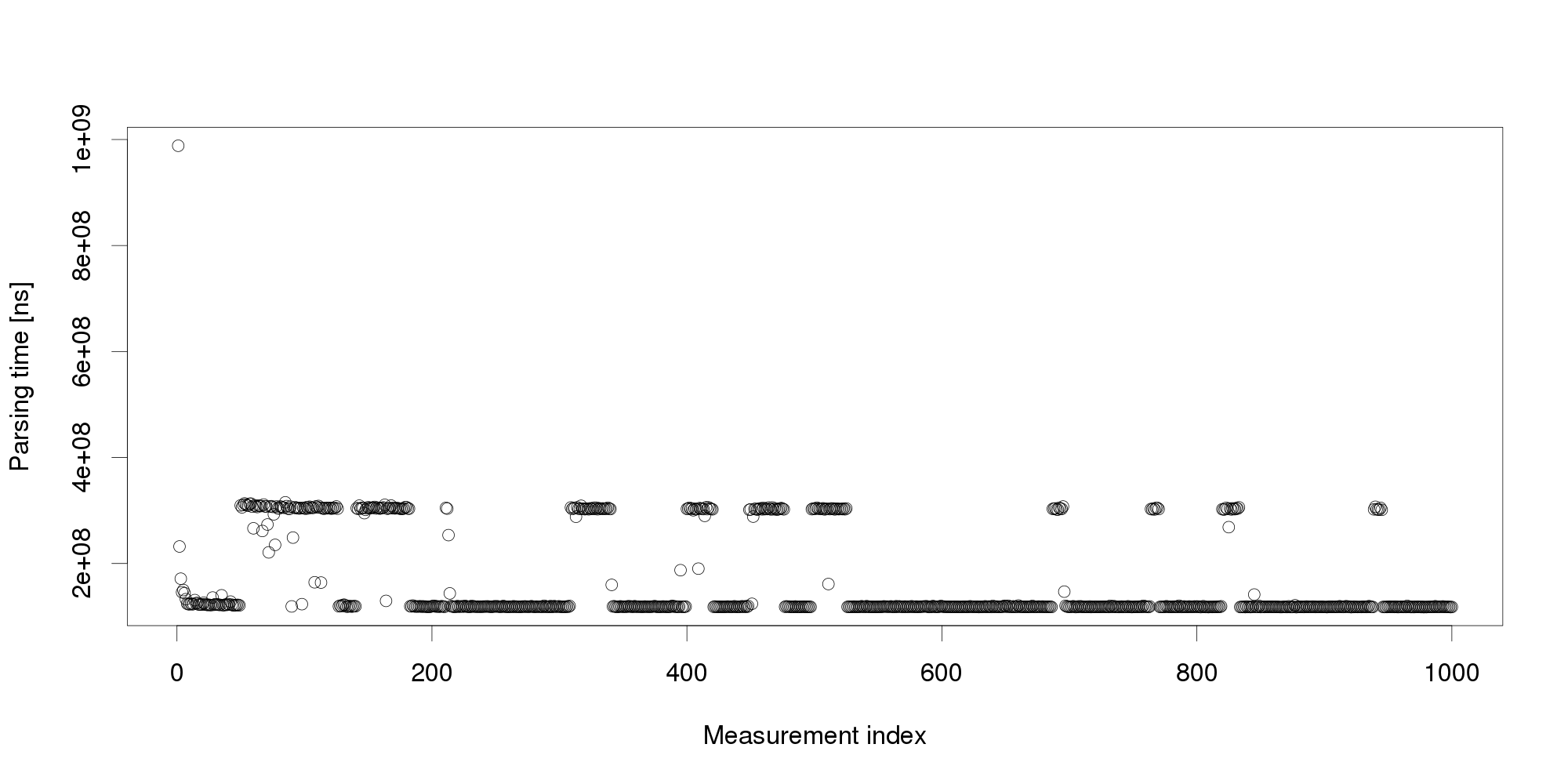 The graph shows that the change we have observed in the first 100 measurements is actually a common pattern. The XML processing server exhibits multiple performance modes that change at irregular intervals, and the processing time does not seem to stabilize in a reasonably short interval. More measurements after restart also show that the modes themselves are not necessarily stable:
The graph shows that the change we have observed in the first 100 measurements is actually a common pattern. The XML processing server exhibits multiple performance modes that change at irregular intervals, and the processing time does not seem to stabilize in a reasonably short interval. More measurements after restart also show that the modes themselves are not necessarily stable:
Experience indicates this is not an unusual behavior. On the contrary, similar behavior can be observed with many software systems, and is often made even worse by additional measurement noise (here, we have measured the data under very stable controlled conditions to demonstrate our point). Obviously, mere threshold detection is not useful to identify changes.
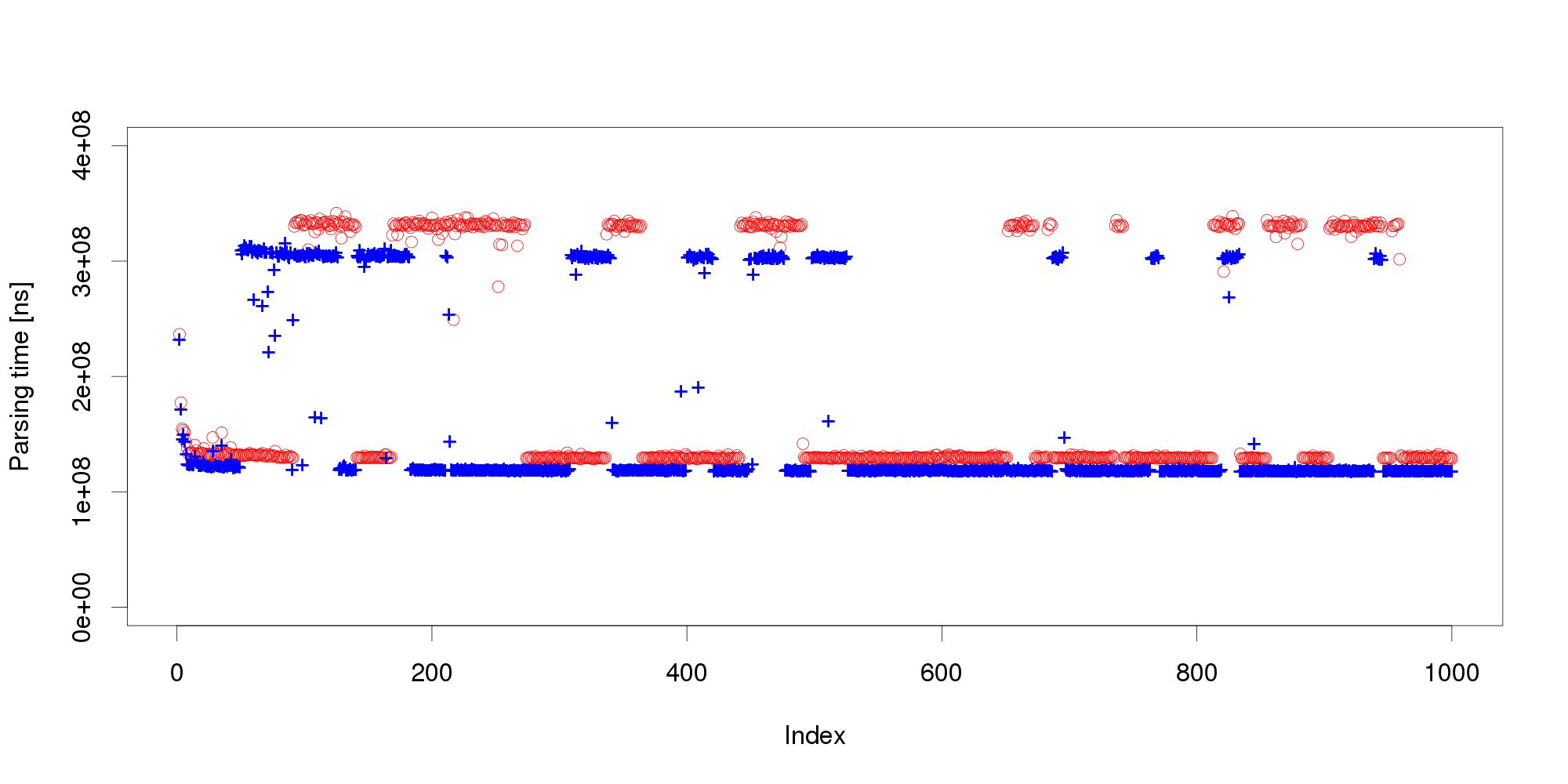
We address the issue with a novel non-parametric method that first learns what is an insignificant change to then detect the significant ones. The method bootstraps from historical data to compute the statistical properties of performance measurements under circumstances that do not require adaptation. Once this is done, the method requires only a few measurements to reliably detect whether they represent a significant performance change. To illustrate our results, we subject the XML processing server to a changing workload and use both our non-parametric method and Welch's t-test to detect changes in performance:
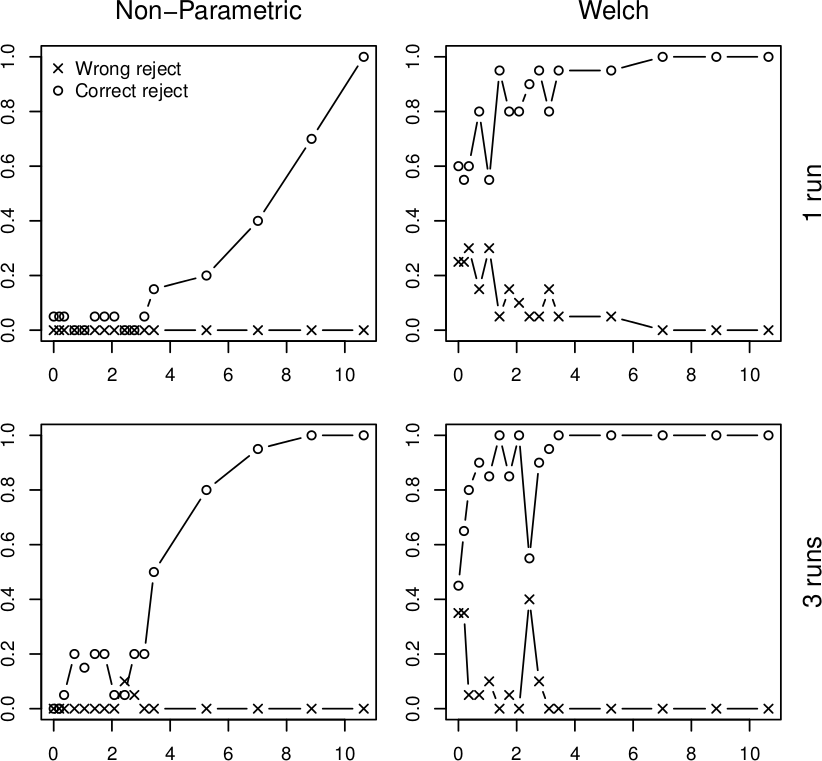
In all four graphs, the x axis shows the percentual change in workload size, the y axis gives the probability of detecting this change. The top row shows the detection after a single measurement, the bottom row does the same for three measurements. The "o" points mark correct change detections, the "x" points mark situations where the direction of the change was not detected correctly. We can see that in realistic conditions, the Welch's t-test would lead to frequent incorrect adaptation that our non-parametric method prevents. More details upon request (a publication is under review).
Vojtěch Horký
CUNI, Prague
Engineering Distributed Adaptive Systems using Components
Traditional software engineering methodologies together with related programming paradigms have long been guiding the procedure of building software systems through the requirements and design phase to testing and deployment. In particular, engineering paradigms based on the notion of components have gained a lot of popularity as they support separation of concerns - extremely valuable when dealing with systems of high complexity.
It seems, though, that these traditional methodologies and paradigms are not sufficient when exploited in the domain of continuously changing, massively distributed and dynamic systems, such as the ones we explore in the ASCENS project. These systems need to adjust to changes in their architecture and environment seamlessly or, even better, acknowledge the absence of absolute certainty over their (constantly changing) architecture and environment. An appealing research direction seems to be the decomposition of such systems into components able to operate upon temporary and volatile information in an autonomous and self-adaptive fashion. From the software engineering perspective, two main challenges arise:
- What are the correct low-level abstractions (models, respective paradigms) that will allow for separation of concerns?
- How can we devise a systematic approach for designing such systems, exploiting the above abstractions?
In response, we propose the DEECo component model (stands for Dependable Emergent Ensembles of Components). The goal of the component model is allow for designing systems consisting of autonomous, self-aware, and adaptable components, which are implicitly organized in groups called ensembles. To this end, we propose a slightly different way of perceiving a component; i.e., as a self-aware unit of computation, relying solely on its local data that are subject to modification during the execution time. The whole communication process relies on automatic data exchange among components, entirely externalized and automated within the runtime. This way, the components have to be programmed as autonomous units, without relying on whether/how the distributed communication is performed, which makes them very robust and suitable for rapidly-changing environments.
Main Concepts
DEECo is centered around two first-class concepts: component and ensemble. These two concepts closely reflect fundamentals of the SCEL specification language. In fact, DEECo is meant to be a component model that provides software engineering constructs for SCEL concepts. Consequently, the behavior of a system of DEECo components and ensembles can be described in SCEL in a straightforward way. The two first-class DEECo concepts are in detail elaborated below:
Component
A component is an autonomous unit of deployment and computation. Similar to SCEL, it consists of:
- Knowledge
- Processes
Knowledge contains all the data and functions of the component. It is a hierarchical data structure mapping identifiers to (potentially structured) values. Values are either statically typed data or functions. Thus DEECo employs statically-typed data and functions as first-class entities. We assume pure functions without side effects.
Processes, each of them being essentially a “thread”, operate upon the knowledge of the component. A process employs a function from the knowledge of the component to perform its task. As any function is assumed to have no side effects, a process defines mapping of the knowledge to the actual parameters of the employed function (input knowledge), as well as mapping of the return value back to the knowledge (output knowledge). A process can be either periodic or triggered. A process can be triggered when its input knowledge changes or when a given condition on the component’s knowledge (guard) is satisfied.
Ensemble
Ensembles determine composition of components. Composition is flat, expressed implicitly via a dynamic involvement in an ensemble. An ensemble consists of multiple member components and a single coordinator component. The only allowed form of communication among components is communication between a member and the coordinator in an ensemble. This allows the coordinator to apply various communication policies.
Thus, an ensemble is described pair-wise, defining the couples coordinator – member. An ensemble definition consists of:
- Required interface of the coordinator and a member
- Membership function
- Mapping function
Interface is a structural prescription for a view on a part of the component’s knowledge. An interface is associated with a component’s knowledge by means of duck typing; i.e., if a component’s knowledge has the structure prescribed by an interface, then the component reifies the interface. In other words, an interface represents a partial view on the knowledge.
Membership function declaratively expresses the condition, under which two components represent the pair coordinator-member of an ensemble. The condition is defined upon the knowledge of the components. In the situation where a component satisfies the membership functions of multiple ensembles, we envision a mechanism for deciding whether all or only a subset of the candidate ensembles should be applied. Currently, we employ a simple mechanism of a partial order over the ensembles for this purpose (the “maximal” ensemble of the comparable ones is selected, the ensembles which are incomparable are applied simultaneously).
Mapping function expresses the implicit distributed communication between the coordinator and a member. It ensures that the relevant knowledge changes in one component get propagated to the other component. However, it is up to the framework when/how often the mapping function is invoked. Note that (except for component processes) the single-writer rule applies also to mapping function. We assume a separate mapping for each of the directions coordinator-member, member-coordinator.
The important idea is that the components do not know anything about ensembles (including their membership in an ensemble). They only work with their own local knowledge, which gets implicitly updated whenever the component is part of a suitable ensemble.
Example
To illustrate the above-described concepts, we’ll give an example from the Science Cloud case-study. In this scenario, several interconnected, heterogeneous network nodes (execution nodes, storage nodes) run a cloud platform, on which 3rd-party services are being executed. Moreover, the nodes can dynamically enter/leave the network. Provided an external mechanism for migrating a service from one (execution) node to another, the goal is to “cooperatively distribute the load of the overloaded (execution) nodes in the network.”
Solution in a Nutshell
Before describing the solution in DEECo concepts, we will give an outline of the final result. Basically, for the purpose of this illustration, we consider a simple solution, where each of the nodes tracks its own load and if the load is higher than a fixed threshold, it selects a set of services to be migrated out. Consequently, all the nodes with low-enough load (determined by another fixed threshold) are given information about the services selected for migration, pick some of them and migrate them in using the external migration mechanism.
The challenge here is to decide which of the nodes the service information should be given to and when, since the nodes join and leave the network dynamically. In DEECo, this is solved by describing such a node interaction declaratively, so that it can be carried out in an automated way by the runtime framework when appropriate.
Realization in DEECo
Specifically, we first identify the components in the system and their internal knowledge. In this example, the components will be all the different nodes (execution/storage nodes) running the cloud platform (Figure 1). The inherent knowledge of execution nodes is their current load, information about running services, etc. We expect an execution node component to have a process, which determines the services to be migrated in case of overload. Similarly, the inherent knowledge of the storage nodes is their current capacity, filesystem, etc.
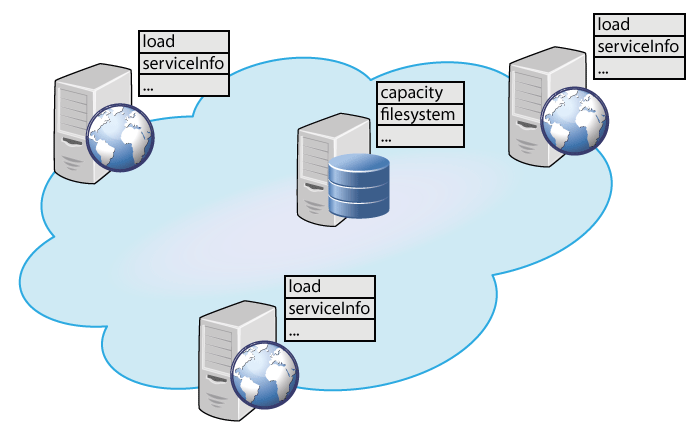
Figure 1. Components representing the cloud nodes and their inherent knowledge.
The second step is to define the actual component interaction and exchange of their knowledge. In this example, only the transfer of the information about services to be migrated from the overloaded nodes to the idle nodes is defined. The interaction is captured in a form of an ensemble definition (Figure 2), thus representing a “template” for interaction. Here, the coordinator, as well as the members, has to be an execution node providing the load and serviceInfo knowledge entries. Having such nodes, whenever the (potential) coordinator has the load above 90% and a (potential) member has the load below 20% (i.e., the membership function returns true), the ensemble is established and its mapping function is executed (possibly in a periodic manner). The mapping function in this case ensures exchanging the information about the services to be migrated from the coordinator to the members of the ensemble.
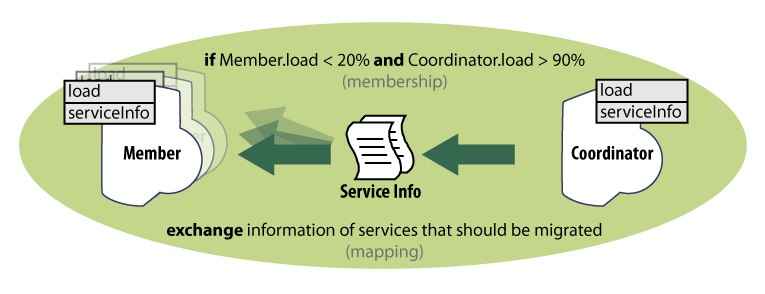
Figure 2. Definition of an ensemble that ensures exchange of the services to be migrated.
When applied to the current state of the components in the system, an ensemble - established according to the above-described definition - ensures an exchange of the service-to-be-migrated information among exactly the pairs of components meeting the membership condition of the ensemble (Figure 3).
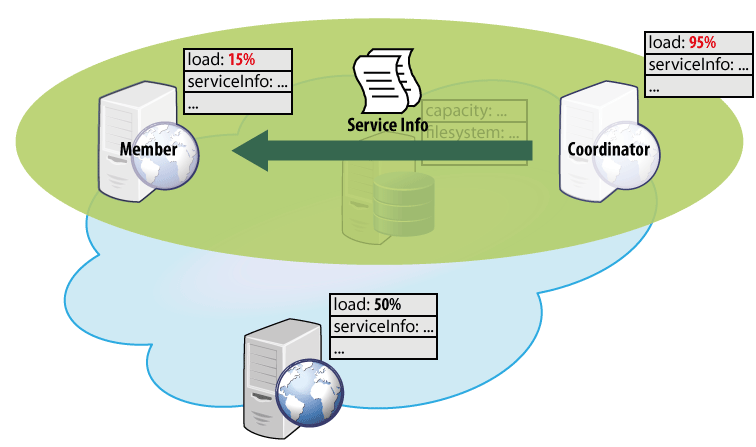
Figure 3. Application of the ensemble definition from Figure 2 to the components from Figure 1.
According to the exchange of service information, the member nodes then individually perform service migration via the external (i.e., outside of DEECo) migration mechanism.
Current Implementation & Future Vision
As for implementation, we work on a prototype based on distributed tuple spaces and implemented in Java. The sources, as well as documentation and examples, can be found at https://github.com/d3scomp/JDEECo.
We envision that the component model outlined here will serve as the basis for a design methodology that will exploit the presented abstractions and help in building long-lasting systems of service-components and service-component ensembles.
ASCENS in Quest of Awareness-Rich Technology
The ASCENS project aims at bringing awareness into technical systems. Formalisms, linguistic constructs and programming tools should be developed featuring high level of autonomous and adaptive behavior. Rigorous and sound concepts will be used to reason and prove system properties, but how can we judge the project’s pragmatic significance? The impact and practical value of the ASCENS project results will be evaluated on e-mobility, cloud computing and swarm robotics application domains. The three novel application domains look complex and fairly different and one may ask: isn’t each problem difficult enough? Why solving all three at once?
1. What E-mobility, Cloud Computing and Swarm of Robots Have in Common?
E-mobility is a vision of future transportation by means of electric vehicles network allowing people to fulfill their individual mobility needs in an environmental friendly manner.
Cloud computing is an approach that delivers computing (resources) to users in a service-based manner, over the internet.
Swarm robotics deals with creation of multi-robot systems that through interaction among participating robots and their environment can accomplish a common goal, which would be impossible to achieve by a single robot.
At a first glance e-cars and transportation, distributed computing on demand and swarm robotics have nothing in common!
1.1 Sharing and Collectiveness
In order to cover longer distances, an e-vehicle driver must interrupt the journey to either exchange or re-charge the battery. Energy consumption has been the major obstacle in a wider use of e-vehicles. Alternative strategy is to share e-vehicles in a way that optimizes the overall mobility of people and the spending of energy. In other words: when my battery is empty – you will take me further if we go towards the same location and vice versa.
The processing statistics show that most of the time computers are idle – waiting for input to do some calculations. Computers belong amongst fastest and at the same time most wasted devices man has ever made. And they dissipate energy too. Cloud computing overcomes that problem by sharing computer resources and making them better utilized. In another words if my computer is free – it can process your data and vice versa; or even better, let us have light devices and leave a heavy work for the cloud.
A swarm indicates a great number of things in motion. Swarm robots dynamically form different shapes in order to solve a collective assignment. Swarm of robots can perform much more as a group than any single element can do on its own. In other words, what we cannot achieve alone, we may manage together.
At a closer look “sharing and collectiveness” are common characteristics of all three application domains!
1.2 Awareness and Knowledge
E-mobility can support coordination only if e-vehicles know their own restrictions (battery state), destinations of users, re-charging possibilities, parking availabilities, the state of other e-vehicles nearby. With such knowledge collective behavior may take place, respecting individual goals, energy consumption and environmental requirements.
Cloud computing deals with dynamic (re-)scheduling of available (not fully used) computing resources. Maximal utilization can only be achieved if the cloud is “aware” of the users’ processing needs and the states of the deployed cloud resources. Only with such a knowledge a cloud can make a good utilization of computers while serving individual users needs.
Each robot in a swarm needs to know its own and the others’ location and capabilities as well as an overall assignment. Only then a swarm can achieve the common goal.
At a closer look “awareness” of own potentials, restrictions and goals as well as those of the others is a common characteristic. All three domains require self-aware, self-expressive and self-adaptive behavior.
1.3 Dynamic and Distributed Optimization
E-mobility is a distributed network that manages numerous independent and separate entities such as e-vehicles, parking slots, re-charge stations, drivers. Through collective and awareness-rich control strategy the system may dynamically re-organize and optimize the use of energy while satisfying users’ transportation needs.
Cloud computing actually behaves as a classical distributed operating system with a goal to maximize operation and throughput and minimize energy consumption, performing tasks of multiple users.
Swarm robotics deals with coordination of a collection of individual robots in order to optimize control strategy through interaction among the robots and the environment.
At a closer look “dynamic and distributed optimization” is inherent characteristic of the control environment for all three application domains.
2. Again, What E-mobility, Cloud Computing and Swarm of Robots Have in Common?
Control systems for all the three domains have many common characteristics: they are highly collective, constructed of numerous independent entities that share common goals. Their elements are both autonomous and cooperative featuring a high level of self awareness and self expressiveness. A complex control system built out of such entities must be robust and adaptive offering maximal utilization with minimal energy and resource use.
3. What the three domains have to do with ASCENS Project?
Formal definition, programming and controlling of complex massively parallel distributed system that feature awareness, autonomous and collective behavior, adaptive optimization and robust functioning are grand challenges of computer science. These challenges are present in most of complex control systems and they are the motivation and inspiration for the ASCENS project. The consortium gathered scientists from different fields in effort to offer novel and scientifically sound concepts and approaches:
- SCE - service–component ensembles as means to dynamically structure independent and distributed system entities
- Modeling and formalization of the fundamental SCE properties as means to rigorously reason about autonomous behavior and aware-rich networking, proving that important system requirements hold
- linguistic support for programming SCEs, expressing awareness and exchanging knowledge among system entities
- adaptive and knowledge-rich software environments and tools, expressing and deploying self-awareness and self-expression in technical systems
(see the ASCENS project goal [http://www.ascens-ist.eu/]). Consequently three different application domains are selected to test the pragmatic significance of the envisaged project concepts and results.
4. What should be the impact of ASCENS Solutions?
The ASCENS project calls for a new generation of technical solutions (techno-sphere) that would be better integrated into our biosphere by mimicking some natural phenomena like awareness, swarm behavior and adaptation. The ultimate rationale is: our resources are not endless thus our technical innovations need to be optimized and self- and energy-aware. We cannot for ever allow ourselves a luxury of driving own cars (on a global earth with increasing population and decreasing energy resources); we cannot for ever allow ourselves the luxury of switching on powerful computers that waste energy without doing much processing. We cannot neglect the usefulness of a swarm behavior (so much present in the nature) that teaches us how simple element can perform complex endeavor in a collective effort. The nature obviously achieves perfection through simplicity. Can we mimic that?
As you do not buy a cow when you need milk, you do not need to possess a car if you want to have free mobility; you do not require a powerful computer if you have processing necessities, you do not need a complex robot if you want automatic assistant. We should be oriented to hire and be charged per use rather than to buy and possess things as this may be a proper way to optimize the use of our precious resources.
To make such a mental and behavioral transition we need better control systems. We hope the ASCENS approach with its generic solutions for a wide class of applications, is a grand step in this direction.
Cloud Application Architectures
Infrastructure cloud services offer very powerful capabilities to utilize infrastructure resources in a very dynamic model. Instead of having minimum usage periods of month or even years the usage can be limited to only a couple of hours. These capabilities allows an application to dynamically adjust the infrastructure usage to the current requirement, but it also requires the application to be compliant to some cloud architecture principles. In this post we will briefly describe the different application architectures and also discuss the up- and downsides.
Basic requirements
In addition to the application architecture compliance also the some requirements must be met by the application in order to make the use of an infrastructure cloud as the basic infrastructure useful. From the following requirements at least one criteria must be met by the cloud application: dynamic scalability, broad network access, high failover requirements. If none of these requirements for the application in question is given the infrastructure cloud is not an appropriate runtime environment.
The requirement to dynamically scale an application can be driven from different sources. Many applications require different amounts of infrastructure due to the business logic (e.g. in the case of scientific calculations) or the user interaction (e.g. in the case of web-applications).
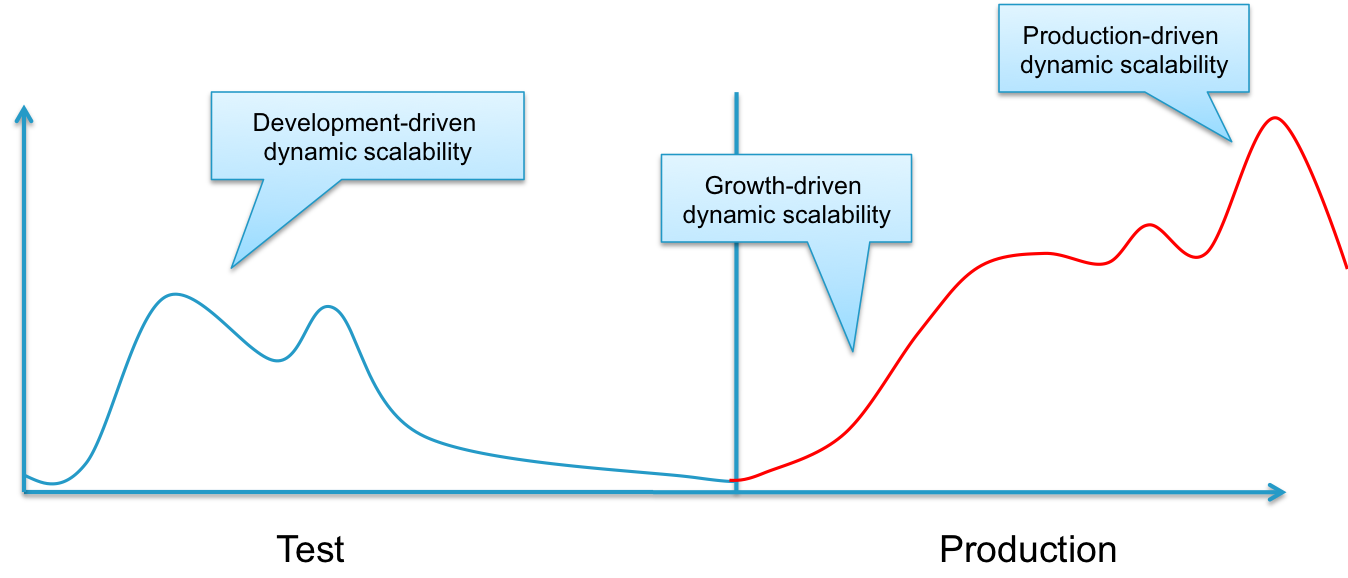
Furthermore along the entire lifecycle of an application the requirement for dynamic ressources is triggered differently as depicted in the figure above.
Broad network access is often required for applications that are accessed by a huge number of users from different networks. In this case the positioning of the application in the cloud makes the access simpler to realize and more secure.
Finally the cloud can help to create a very high availability. When using deploying single applications with multiple tiers across a set of decoupled datacenters the availability of the application can be raised to a higher level, as the combined risk (of both datacenters failing at the same time) is the multiplication of the individual risks.
Architectural Principles
After having reviewed the basic requirements for an application to be usefully deployed within the cloud this section reviews principles of application architectures that can help an application to make use of the cloud capabilities.
There are two main aspects: state management and scalability. The following table shows how these principles
Stateful vs. Stateless:
Stateful systems have substantial information on the current state of the application in the memory, or in a cache that cannot be recovered when the system is being restarted. Stateless systems in turn are keeping as little data as possible within a non-recoverable repository. Usually stateless applications are persisting all of their data instantly and keep very little information “in-flight”. Stateless systems have the huge advantage that recovery processes are much simpler. When a stateless system needs to be restarted after an uncontrolled stop it can simply restore the state from the data repository. If the system is developed in a very clean stateless way there is even no such thing like a recovery process as every operation starts without an initial state and thus takes the input values from the data repository. Therefore stateless systems have less rigid requirements for the underlying infrastructure.
Vertical vs. Horizontal
Application design can also fundamentally differ in the way scalability is designed. An application can be either scaling up or scaling out. Scaling up means increasing the performance of a single operating system to support the higher demands of the application. Scaling out means adding additional operating system and application instances for instance in a cluster and the application will coordinate the load distribution. Typical examples of scale out architectures are webserver clusters that serve a single website.
The two scaling principles are depicted in the figure below.
| Figure | Description |
|---|---|
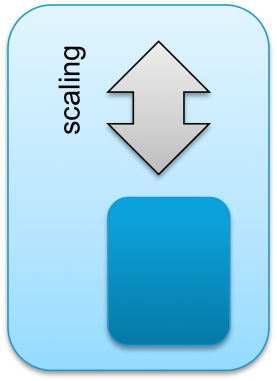 |
Scaling is done by increasing single instances:
Operating System handles the additional resources transparent to the application. |
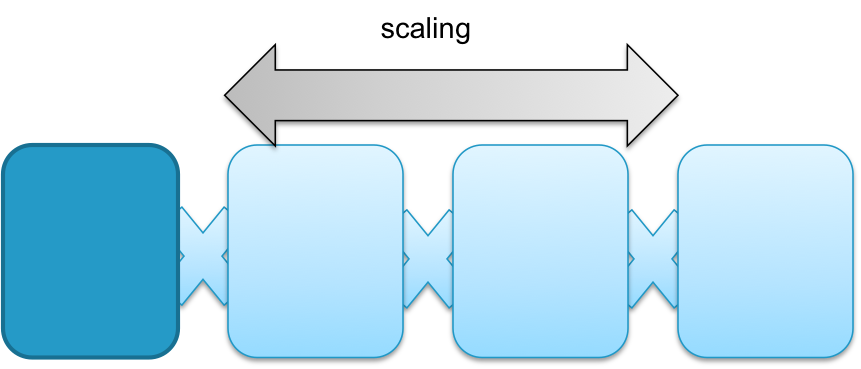 |
Scaling is done by increasing the amount of instances:
Application handles the load independent from the operating system. |
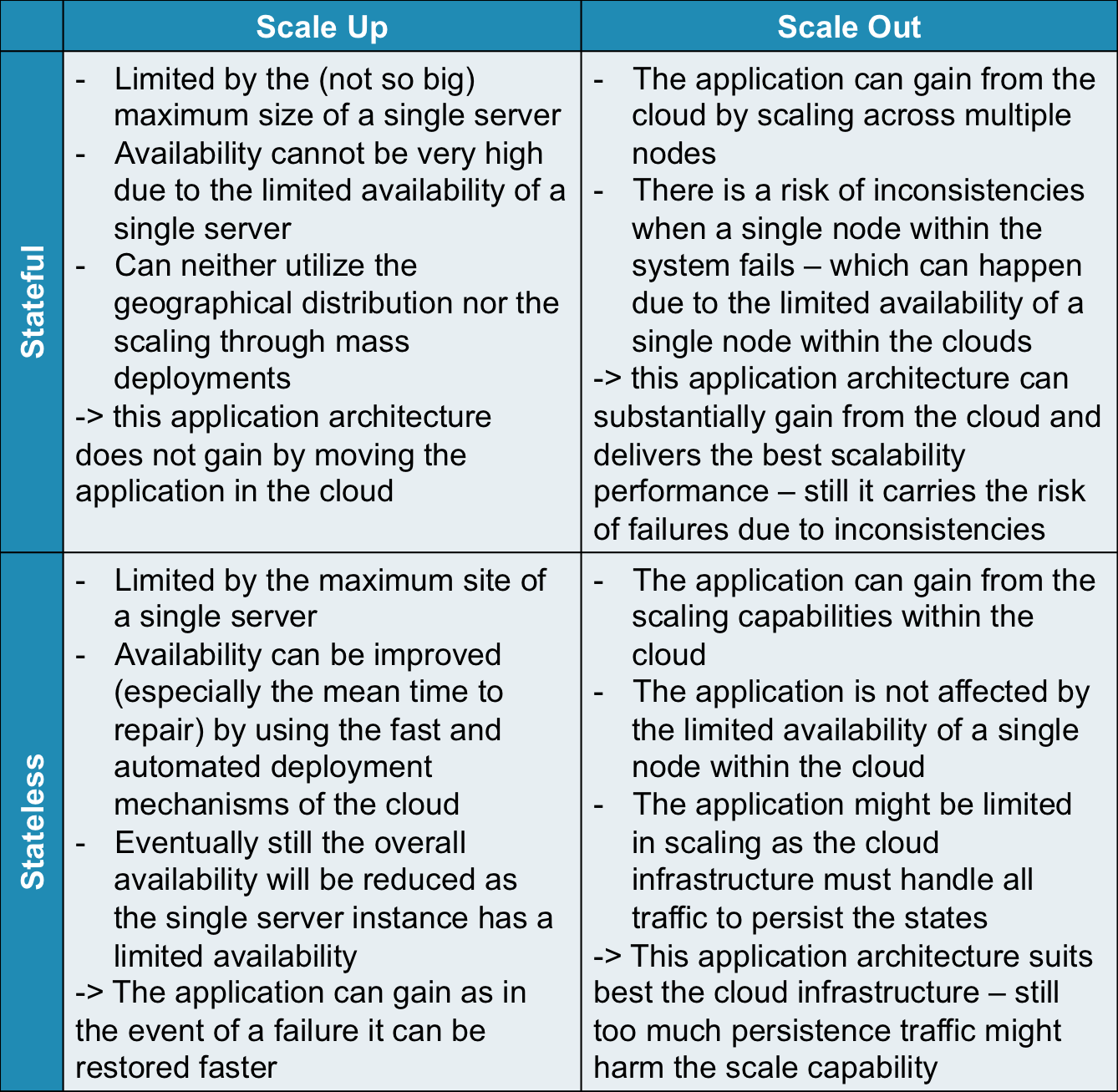
Both scalability designs have advantages and disadvantages. A short comparison can be found in the table below.
| Scale Up | Scale Out |
|---|---|
|
|
When looking the two different aspects (state management and scalability) in a combined way many applications that scale out are following the principles of statelessness, whereas many scale-up applications contain much more state within the application.
The application architecture for the cloud
How to derive from the requirements and the architectural principles a design decision for the cloud? First the physical design of the infrastructure clouds has to be reviewed briefly.
Infrastructure clouds are often build using standard sized X86 servers, each server neither being very powerful nor having a particular high availability. The power of the cloud comes from the huge mass of similar servers that are combined in a single cloud. This cloud can be within one datacenter or even across multiple locations. The later setup can often be found when the size of the cloud makes it difficult to install all servers and storage pools within one datacenter.
The following table shows how the principles match the infrastructure setup and how they support the requirements.
So in conclusion for the application architecture the cloud requires a scale out architecture. The state management of the application depends on a trade-off between the consistency requirement and the scalability requirement. Many cloud applications follow a partially stateless model - with the important data being persisted instantly whereas other data elements are not persisted and will be lost in the case of a failure of a single node.
Dreaming of fluffy clouds
Clouds. For a while now I've been under impression that they are present virtually everywhere. Even on beautiful sunny days in spring people seem to be fascinated by clouds. What do they see in them, I wonder. It is the extensive media coverage they receive, which suggests that they might be an important trend in computing. But how do they affect me and my every day life?
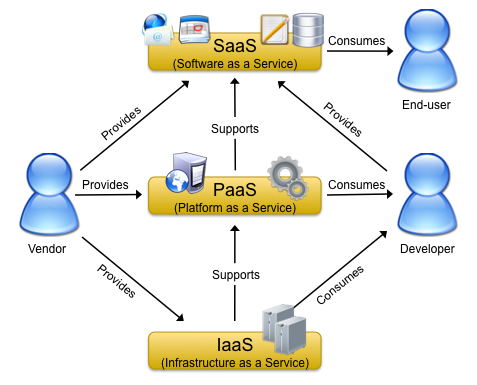
A variety of attempts has been made to describe and characterize cloud computing from different points of view. The generally agreed upon idea behind this concept is the provisioning of services and IT-resources in a dynamic and on-demand way over the Internet, backed by different billing models, such as subscriptions or pay-as-you-go. This definition is quite broad and does not limit cloud computing to certain types of services or IT-resources. Yet, today we typically associate cloud-based products with one of three categories, which address infrastructure, platform and software needs.
The following image is based on a publication by Briscoe and Marinos ("Digital Ecosystems in the Clouds: Towards Community Cloud Computing") and presents a view on these three types of clouds with the relationships among them and between vendors and users.
- Infrastructure-as-a-Service (IaaS) is concerned with the provisioning of storage and processing power, the latter of which is typically implemented and provided in terms of so-called virtual machines. A virtual machine is a computer that is simulated on top of a phyiscal machine and that can be fully configured by the user, (virtual) hardware- and software-wise. IaaS can support ...
- Platform-as-a-Service, which is a means of providing an execution platform for user-provided applications in the cloud. Although not as customizable as IaaS clouds, PaaS clouds typically have the benefit of providing a simple and efficient way for the implementation of application for the Internet. They form an abstraction layer over actual (physical or virtual) machines and can thereby provide a developer-friendly ecosystem for application development and deployment. Based on such a platform, vendors and users may provide ...
- Software-as-a-Service. Actual products for end-users, such as e-mail and calendars, but also web-based document processing or image mangement. Think Google Apps and Microsoft Office Live, just to give to examples of SaaS cloud services, although most other Web 2.0 products may as well be categorized as SaaS.
 Since its inception, cloud computing has been established as a viable alternative to traditional in-house provisioning of IT-resources and is continously gaining more acceptance and use in both personal and corporate environments. It enables companies to outsource their infrastructure and service needs, to save investments in local computing resources and the management thereof, and to react to changing requirements more flexibly since cloud resources can be requested and used on demand.
Since its inception, cloud computing has been established as a viable alternative to traditional in-house provisioning of IT-resources and is continously gaining more acceptance and use in both personal and corporate environments. It enables companies to outsource their infrastructure and service needs, to save investments in local computing resources and the management thereof, and to react to changing requirements more flexibly since cloud resources can be requested and used on demand.
However, with the use of these public clouds, as offered by Amazon, Microsoft and Google, to name some of the big providers, companies incur a dependency on these external providers. The reliability of their service provisioning is a critical factor for the continuing success of the company and is typically detailed in service level agreements between the provider and the consumer among other quality-of-service characteristics.
Nevertheless, cloud computing outages have caused severe problems in the past with service and infrastructure down-times ranging from a few minutes to multiple hours, as illustrated by Alex Williams in his article "Top 5 Cloud Outages of the Past Two Years: Lessons Learned". Today the analysis and repair of these problems is typically performed by human operators, which makes it difficult to predict the time required for the reestablishment of cloud availability to normal levels or to levels as specified in service level agreements. In order to be able to provide robust cloud services it is therefore necessary to automate at least large parts of these analysis and repair steps.
In the ASCENS project we pursue this goal by introducing a sense of self-awareness to clouds to enable autonomous reactions to changes in the infrastructure, such as the abrupt departure of computation nodes, to give an example. By enabling autonomous reactions, we seek to be able to deliver more robust cloud services with higher quality-of-service levels. This idea of self-healing systems is something we think is vital for delivering reliable cloud services as it transfers the responsibility of fault analysis and repair from human operators to machines, which are able to perform these actions in shorter time spans thereby reducing potential downtimes of services and improving customer satisfaction.
Clouds. The vision of making data and services accessible from anywhere at any time is very appealing and fits in perfectly with our changing lifestyle and higher mobility. Music, movies, documents, pictures, ... No longer are we limited by the fact that these artifacts are stored locally on some machine that we first need to switch on in order to gain access. Our data and important services, such as e-mail and calendars, live in the Cloud and are available to us on desktop computers, notebooks, smartphones and other portable devices. At the same time we incur a dependency on being connected to the Internet and to our cloud providers. If the provider is not able to service our requests, well, then we are blocked from accessing our data. It is therefore crucial that cloud services are robust and highly-available. This is what we strive for in the ASCENS project.